第6章 手続き部
6.1 概要
手続き部では、実行用プログラムの処理手順を書く。手続き部は、データ部の後に書く。
処理を書く必要がない場合、手続き部を省略することができる。(*1)
(*1) SIT COBOLは、手続き部は必須である。
6.2 手続き部の構成(PROCEDURE DIVISION)
手続き部は、宣言部分と手続き部分で構成する。
宣言部分は、DECLARATIVESで始まり、END
DECLARATIVESで終わる。
手続き部分は、1つの段落、連続したいくつかの段落の組、1つの節、または連続したいくつかの節の組で構成する。節に属するすべての段落は、節の中にまとめて書く。
書き方1:宣言部を書かない場合(その1)
PROCEDURE DIVISION.
{ 節名 SECTION.
[段落名.
[ 完結文 ] … ] … } …
書き方2:宣言部を書かない場合(その2)
PROCEDURE DIVISION.
[段落名.
[ 完結文 ] … ] …
書き方3:宣言部を書く場合
PROCEDURE DIVISION.
DECLARATIVES.
{ 節名 SECTION.
USE文
[段落名.
[ 完結文 ] … ] … } …
END DECLARATIVES.
{ 節名 SECTION.
[段落名.
[ 完結文 ] … ] … } …
(※) SIT COBOLは、手続き部分の節名と段落名の両方を省略することができる。
節
節は、節の見出し(“節名 SECTION.”)といくつかの段落で構成する。段落は、省略することもできる。節の範囲は、節の見出しから以下のいずれかの地点までの部分である。
- 次の節の直前まで。
- 手続き部の終わりまで。
- 宣言部分の場合、END DECLARATIVESまで。
段落
段落は、段落名といくつかの完結文で構成する。段落名の後には、分離符の終止符を書かなければならない。完結文は、省略することもできる。段落の範囲は、段落名から以下のいずれかの地点までの部分である。
- 次の段落名の直前まで。
- 次の節名の直前まで。
- 手続き部の終わりまで。
- 宣言部分の場合、END DECLARATIVESまで。
文
完結文は、いくつかの文で構成し、分離符の終止符で終わる。手続き部に書いた文は、原則として、プログラムに書いた順に実行される。
文には、条件文、無条件文および翻訳指示文の3種類がある。
- 「条件文」は、次に行う動作が条件の真理値によって決まる文である。
- 「無条件文」は、次に行う動作が無条件に決まる文である。
- 「翻訳指示文」は、翻訳時の動作を指示する文である。翻訳指示文は、実行時には意味を持たない。(*1)翻訳指示文は、COPY文、REPLACE文およびUSE文である。翻訳指示文のCOPY文およびREPLACE文は、手続き部以外にも書くことができる。COPY文およびREPLACE文は、“原始文操作”で説明する。
(*1) SIT COBOLはインタプリタであり、実行直前に解釈される文である。
条件文は、文の最後に明示範囲符を書くことにより、無条件文にすることができる。「明示範囲符」とは、“END-動詞”の形式の語である。例えば、ON
SIZE
ERROR指定付きのADD文は、END-ADD指定なしのときは条件文、END-ADD指定付きのときは無条件文である。
無条件文は、そのいくつかを連続して書くことができる。無条件文の間には、分離符を書くこともできる。“書き方”で“無条件文-n”と示しているところには、分離符の終止符を含まない、いくつかの連続した無条件文を書くことができる。
下表に、条件文と無条件文を示する。
| 文 | 条件文と無条件の区別 |
| ACCEPT文 | 無条件文 |
| ADD文 |
ON SIZE ERROR 指定またはNOT ON SIZE ERROR
指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| ALTER文 | 無条件文 |
| CALL文 |
ON OVERFLOW 指定、ON EXCEPTION指定またはNOT ON
EXCEPTION指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| CANCEL文 | 無条件文 |
| CLOSE文 | 無条件文 |
| COMPUTE文 |
ON SIZE ERROR 指定またはNOT ON SIZE ERROR 指定付きの場合、条件文(*1)。
これらのどの指定もない場合、無条件文。 |
| CONTINUE文 | 無条件文 |
| DELETE文 |
INVALID KEY 指定またはNOT INVALID KEY 指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| DISPLAY文 |
ON EXCEPTION指定またはNOT ON EXCEPTION指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| DIVIDE文 |
ON SIZE ERROR 指定またはNOT ON SIZE ERROR
指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| EVALUATE文 | 条件文(*1) |
| EXIT文 | 無条件文 |
| EXIT PERFORM文 | 無条件文 |
| EXIT PROGRAM文 | 無条件文 |
| GO TO文 | 無条件文 |
| IF文 | 条件文(*1) |
| INITIALIZE文 | 無条件文 |
| INSPECT文 | 無条件文 |
| MERGE文 | 無条件文 |
| MOVE文 | 無条件文 |
| MULTIPLY文 |
ON SIZE ERROR 指定またはNOT ON SIZE ERROR
指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| OPEN文 | 無条件文 |
| PERFORM文 | 無条件文 |
| READ文 |
AT END指定、NOT AT END指定、INVALID KEY 指定またはNOT INVALID KEY
指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| RELEASE文 | 無条件文 |
| RETURN文 | 条件文(*1) |
| REWRITE文 |
INVALID KEY 指定またはNOT INVALID KEY 指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| SEARCH文 | 条件文(*1) |
| SET文 | 無条件文 |
| SORT文 | 無条件文 |
| START文 |
INVALID KEY 指定またはNOT INVALID KEY 指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| STOP文 | 無条件文 |
| STRING文 |
ON OVERFLOW 指定またはNOT ON OVERFLOW 指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| SUBTRACT文 |
ON SIZE ERROR 指定またはNOT ON SIZE ERROR
指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| UNLOCK文 | 無条件文 |
| UNSTRING文 |
ON OVERFLOW 指定またはNOT ON OVERFLOW 指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
| WRITE文 |
INVALID KEY 指定、NOT INVALID KEY 指定、END-OF-PAGE 指定またはNOT
END-OF-PAGE
指定付きの場合、条件文(*1)。 これらのどの指定もない場合、無条件文。 |
(*1) 文の最後に明示範囲符を書くことにより、無条件文になる。
次の実行文でない文に制御の明示的な移行を起こす文を、「手続き分岐文」という。手続き分岐文には、以下のものがある。
- ALTER文、CALL文、EXIT文、EXIT PERFORM文、EXIT PROGRAM文、GO TO文、OUTPUT PROCEDURE指定のMERGE文、PERFORM文、およびINPUT PROCEDURE指定またはOUTPUT PROCEDURE指定のSORT文。
完結文
完結文には、完結文を構成する文の種類によって、条件完結文、無条件完結文および翻訳指示完結文の3種類がある。
- 「条件完結文」は、分離符の終止符で終わる条件文である。1つの条件文の前にいくつかの無条件文をつないで、1つの条件完結文にすることができる。
- 「無条件完結文」は、分離符の終止符で終わる無条件文である。いくつかの無条件文をつないで、1つの無条件完結文にすることができる。
- 「翻訳指示完結文」は、分離符の終止符で終わる翻訳指示文である。翻訳指示完結文は、1つの翻訳指示文と分離符の終止符だけで構成しなければならない。
文の範囲
文の範囲を明に指定するために、明示範囲符または分離符の終止符を書くことができる。
明示範囲符は、以下の語である。
- END-ADD、END-CALL、END-COMPUTE、END-DELETE、END-DISPLAY、END-DIVIDE、END-EVALUATE、END-IF、END-MULTIPLY、END-PERFORM、END-READ、END-RETURN、END-REWRITE、END-SEARCH、END-START、END-STRING、END-SUBTRACT、END-UNSTRING、END-WRITE
明示範囲符を書くと、明示範囲符に対応する文の範囲が終了する。以下に、明示範囲符を使って文の範囲を指定する例を示す。
000000 IF A = 1 THEN ...[1]
000000 MOVE A TO B
000000 IF X = 1 THEN ...[2]
000000 MOVE X TO Y
000000 ELSE
000000 MOVE Z TO Y
000000 END-IF ...[2] の IF文の明示範囲符
000000 END-IF ...[1] の IF文の明示範囲符分離符の終止符を書くと、分離符の終止符の前にあるすべての文の範囲が終了する。以下に、分離符の終止符を使って文の範囲を指定する例を示す。
000000 IF A = 1 THEN ...[1]
000000 MOVE A TO B
000000 IF X = 1 THEN ...[2]
000000 MOVE X TO Y
000000 ELSE
000000 MOVE Z TO Y. ... 分離符の終止符により、[1]および[2] の IF文が終了する。6.3 手続き部の見出し
手続き部の見出しは、手続き部の最初に書く。USING指定を書くと、呼ぶプログラムからパラメタを受け取ることができ、RETURNING指定を書くと、呼ばれたプログラムに結果を返すことができる。
書き方
PROCEDURE DIVISION
[ USING {データ名-1} … ]
[ RETURNING データ名-2 ].
構文規則
- プログラムがUSING指定付きのCALL文によって呼び出される場合だけ、そのプログラムの手続き部の見出しにUSING指定を書くことができる。
- USING指定には、呼ぶプログラムから受け渡されるパラメタに対応するデータ名を指定する。呼ぶプログラムのCALL文のUSING指定に書いた項目と、手続き部の見出しのUSING指定に書いたデータ名との対応は、それぞれのUSINGに指定した順に左から右に対応付けられる。
- データ名-1は、以下の規則に従わなければならない。
- 連絡節で定義したデータ項目でなければならない。
- データ名-1のデータ項目のレベル番号は、01または77でなければならない。
- データ名-1のデータ記述項に、REDEFINES句を書いてはならない。ただし、REDEFINES句の右辺には、データ名-1を書くことができる。
- データ名-1の並びに、同じデータ名を書いてはならない。
- RETURNING指定は、プログラム定義に指定できる。
- データ名-2は、連絡節のレベル番号01または77のデータ項目として定義しなくてはならない。データ名-2のデータ記述項は、REDEFINES句を含んではならない。連絡節の他のデータ項目に、REDEFINES データ名-2を書くこともできる。
一般規則
- CALL文のBY CONTENT指定のパラメタは、CALL文の実行後、呼び出されたプログラムの中でデータ名-1によって参照することができる。しかし、呼び出されたプログラムの中でデータ名-1に値を設定しても、呼ぶプログラムでその値を受け取ることはできない。CALL文のBY CONTENT指定のデータ項目に対応する、手続き部の見出しのUSING指定のデータ項目は、用途および文字位置の個数が互いに同じでなければならない。
- CALL文のBY REFERENCE指定のパラメタは、CALL文の実行後、呼び出されたプログラムの中でデータ名-1によって参照することができる。また、呼び出されたプログラムの中でデータ名-1に値を設定すると、呼ぶプログラムでその値を受け取ることができる。CALL文のBY REFERENCE指定のデータ項目に対応する、手続き部の見出しのUSING指定のデータ項目は、文字位置の個数が互いに同じでなければならない。
- CALL文のBY VALUE指定のパラメタは、手続き部の見出しのUSING指定で受け取ることはできない。
- データ名-1の内容は、つねにデータ名-1のデータ記述に従って参照される。
- 呼ばれるプログラムの連絡節で定義したデータ項目は、以下の条件の1つを満足する場合に、手続き部で使うことができる。
- 手続き部の見出しまたはENTRY文のUSING指定に書いたデータ項目である。
- a.の条件を満足するデータ項目に従属するデータ項目である。
- a.またはb.の条件を満足するデータ項目を、REDEFINES句またはRENAMES句の右辺に指定したデータ項目である。
- c.の条件を満足するデータ項目に従属するデータ項目である。
- a.~d.のいずれかの条件を満足するデータ項目に関連する条件名または指標名である。
6.4 文に関する共通の規則
こでは、文に関する共通の規則、および文に共通に書くことができる指定について説明する。
6.4.1 算術式
算術式は、算術演算子と一意名または定数を組み合わせて書く。算術式は、以下の5種類である。
- 数字項目、浮動小数点項目、数字関数、整数関数、数字定数および表意定数ZEROの中の1つを書いたもの。
- 1.の要素を算術演算子でつないだもの。
- 2個の算術式を算術演算子でつないだもの。
- 算術式を括弧で囲んだもの。
- 算術式の前に単項演算子を書いたもの。
算術演算子
算術演算子には、二項演算子と単項演算子がある。算術演算子を下表に示す。
| 分類 | 演算子 | 意味 |
| 二項演算子 | + | 加算 |
| - | 減算 | |
| * | 乗算 | |
| / | 除算 | |
| ** | べき乗(*1) | |
| 単項演算子 | + | 数字定数の+1を掛けることと同じ |
| - | 数字定数の-1を掛けることと同じ |
算術式の書き方の規則
- 算術式で許される一意名、定数、算術演算子および括弧の組合せを、下表に示す。
| — | 後続する要素 | ||||
| 先行する要素 | 一意名または定数 | ( |
単項演算子 +,- |
二項演算子 +,-,*,/,** |
) |
|
単項演算子 +,- |
○ | ○ | — (*1) | — | — |
| ( | ○ | ○ | ○ | — | — |
|
二項演算子 +,-,*,/,** |
○ | ○ | ○ | — | — |
| ) | — | — | — | ○ | ○ |
| 一意名または定数 | — | — | — | ○ | ○ |
—:先行する要素に続いて後続する要素を書くことはできない。
(*1) SIT COBOLは、単項演算子に続けて単項演算子を書くことができる。つまり、’COMPUTE B = - - A’のような書き方が許される。
- 算術式は、単項演算子、左括弧、一意名または定数で始まり、右括弧、一意名または定数で終わらなければならない。
- 算術式中の一意名は、数字項目、数字関数または整数関数でなければならない。算術式中の定数は、数字定数または表意定数ZEROでなければならない。
- 算術演算子の前後には、空白を置かなければならない。ただし、算術演算子と括弧の間の空白は、省略することができる。
- 左括弧と右括弧は一対一に対応付け、左括弧を右括弧より前に書かなければならない。算術式中の最初が単項演算子で、その算術式を一意名または他の演算子に続ける場合には、その単項演算子の直前に左括弧を書かなければならない。(*2)
(*2) SIT COBOLは、単項演算子の直前に左括弧を書かなくともよい。すなわち、’COMPUTE K = I * - J’のような書き方もできる。
算術式の評価規則
- 算術式の評価順序は、括弧を使って指定することができる。括弧を書かないときの算術演算子の評価順序は、以下のとおりである。
1番目: 単項演算子の+、-
2番目: **
3番目: *、/
4番目:
二項演算子の+、-
- 括弧は、以下の場合に使う。
- 同じ順位の算術演算子の間で評価順序を変更したい場合。
- 異なる順位の算術演算子の間で評価順序を変更したい場合。
- 括弧を書くと、括弧の中の算術式が先に評価される。括弧が入れ子になっている場合は、一番内側の括弧の中の算術式が最初に評価され、順次外側が評価される。
- 同じ順位の算術演算子が続いている場合、算術演算子は左から右の順に評価される。
6.4.2 条件式
条件式は、条件が成立している(真である)かまたは成立していない(偽である)かを表す値(真理値)を持つ。条件式は、真理値を検査することによって、プログラムの流れを制御するために使う。条件式は、EVALUATE文、IF文、PERFORM文およびSEARCH文に書くことができる。
条件式には、以下の種類がある。
| 条件式 | 単純条件 | 比較条件 |
| 字類条件 | ||
| 条件名条件 | ||
| スイッチ条件 | ||
| 正負条件 | ||
| 複合条件 | ||
(1) 比較条件
比較条件は、2つの作用対象を比較するために使う。作用対象として、一意名、定数、算術式または指標名を書くことができる。
書き方
{ 一意名-1 | 定数-1 | 算術式-1 | 指標名-1 }
{ IS [ NOT ] GREATER THAN |
IS [ NOT ] LESS THAN |
IS [ NOT ] EQUAL TO |
IS [ NOT ] > |
IS [ NOT ] < |
IS [ NOT ] = |
IS GREATER THAN OR EQUAL TO |
IS >= |
IS LESS THAN OR EQUAL TO |
IS <= }
{ 一意名-2 | 定数-2 | 算術式-2 | 指標名-2 }
(備考)
“>”、“<”、“=”、“>=”および“<=”は、他の記号との混同を避けるために、下線を付けてはならない。
- 比較演算子の左側の作用対象(一意名-1、定数-1、算術式-1または指標名-1)を、「条件の左辺」という。比較演算子の右側の作用対象(一意名-2、定数-2、算術式-2または指標名-2)を「条件の右辺」という。
- 比較条件には、1つ以上の変数を書かなければならない。
- 比較演算子を構成する予約語の前後には、1つ以上の空白を置かなければならない。
- 比較条件では、条件の左辺と右辺を比較演算子に従って比較して、真理値を決定する。比較条件で行われる比較の種類は、比較演算子で決められる。比較演算子の意味を、下表に示す。
| 比較演算子 | 意味 |
| IS [NOT] GREATER THAN およびIS [NOT] > | 左辺が右辺より大きい[左辺が右辺より大きくない](*1) |
| IS [NOT] LESS THAN およびIS [NOT] < | 左辺が右辺より小さい[左辺が右辺より小さくない](*1) |
| IS [NOT] EQUAL TO およびIS [NOT] = | 左辺が右辺と等しい[左辺が右辺と等しくない](*1) |
| IS GREATER THAN OR EQUAL TO およびIS >= | 左辺が右辺より大きいか等しい (*2) |
| IS LESS THAN OR EQUAL TO およびIS <= | 左辺が右辺より小さいか等しい (*3) |
(*2) “IS GREATER THAN OR EQUAL TO”は“IS NOT LESS THAN”と等価であり、“IS >=”は“IS NOT <”と等価である。
(*3) “IS LESS THAN OR EQUAL TO”は“IS NOT GREATER THAN ”と等価であり、“IS <=”は“IS NOT >”と等価である。
- 比較条件での比較の規則については、“比較の規則”を参照のこと。
(2) 字類条件
字類条件は、データ項目の内容の字類を検査するために使う。
書き方
一意名-1 IS [ NOT ] {
NUMERIC |
ALPHABETIC |
ALPHABETIC-LOWER |
ALPHABETIC-UPPER |
字類名
}
(※) SIT COBOLは、字類名を指定することはできない。
- 字類条件では、字類検査の指定に従って一意名-1の内容を検査し、真理値を決定する。字類検査が真になる条件を、下表に示す。
| 字類検査の種類 | 字類検査の内容 |
| NUMERIC 検査 | 一意名-1の内容が数字0、1、2、3、…、9だけからなる、またはこれらに演算符号を付けたものである場合。(*1) |
| ALPHABETIC検査 | 一意名-1の内容が英大文字A、B、C、…、Zと空白からなる、または英小文字a、b、c、…、zと空白からなる、または英大文字と英小文字と空白の組合せからなる場合。 |
| ALPHABETIC-LOWER検査 | 一意名-1の内容が英小文字a、b、c、…、zと空白からなる場合。 |
| ALPHABETIC-UPPER検査 | 一意名-1の内容が英大文字A、B、C、…、Zと空白からなる場合。 |
| 字類名検査 | 一意名-1の内容が、特殊名段落のCLASS 句で指定した文字の組からなる場合。 |
- 一意名-1は、以下のいずれかでなければならない。
- 用途が表示用のデータ項目
- 英数字関数または日本語関数の関数一意名
- 内部10進項目
- NUMERIC検査の場合、一意名-1に以下のデータ項目を指定することはできない。
- 英字項目
- 符号付き数字項目を従属する集団項目
- 日本語項目
- 日本語編集項目
- ALPHABETIC検査、ALPHABETIC-LOWER検査、ALPHABETIC-UPPER検査および字類名検査の場合、一意名-1に以下のデータ項目を指定することはできない。
- 数字項目
- 日本語項目
- 日本語編集項目
- NUMERIC検査が真になる条件は、以下のとおりである。
- 一意名-1のデータ項目に演算符号を指定しなかった場合、その内容が数字だけからなり、かつ演算符号がないとき、真になる。一意名-1が内部10進項目の場合は、その符号部分が16進表現のFのとき真になる。
- 一意名-1のデータ項目に演算符号を指定した場合、その内容が数字だけからなり、かつ有効な演算符号が存在するとき、真になる。有効な演算符号が存在するときとは、以下の場合である。
- 一意名-1のデータ項目のSIGN句にSEPARATE CHARACTERを指定した場合、その符号部分が標準データ形式の“+”または“-”のとき。
- 一意名-1が外部10進項目で、そのSIGN句にSEPARATE CHARACTERを指定しなかった場合、その符号部分が16進表現の3のとき。
- 一意名-1が内部10進項目の場合、その符号部分が16進表現のC、DまたはFのとき。
- NOTを書いた場合、NOTと必要語で1つの字類条件になる。NOTを書くと、真理値の真/偽がNOTを書かなかった場合の逆になる。例えば“NOT NUMERIC”は、作用対象が数字でないとき真になる。
(3) 条件名条件
条件名条件は、条件変数の値が条件名の値と等しいかどうかを調べるために使う。
書き方
条件名-1
- 条件名条件が真になる条件は、以下のとおりである。
- 条件名-1のデータ記述項のVALUE句にTHRUを書かなかった場合、条件変数の値がVALUE句で指定した値と等しいとき真になる。
- 条件名-1のデータ記述項のVALUE句にTHRUを書いた場合、条件変数の値が、VALUE句で指定した値の範囲内(THRUで指定した両端の値も含む)にあるとき真になる。
- 条件変数の値を条件名-1の値と比較するときの規則は、比較条件での比較の規則に従う。比較の規則については、“比較の規則”を参照のこと。
- 条件名条件の例を、以下に示す。
- 条件変数および条件名を、以下のように定義したとする。
000000 02 MONTH PICTURE 99. ... [1]
000000 88 SPRING VALUE 3 THRU 5. ... [2]
000000 88 SUMMER VALUE 6 THRU 8. ... [2]
000000 88 FALL VALUE 9 THRU 11. ... [2]
000000 88 WINTER VALUE 12, 1, 2. ... [2][図の説明]
[1] 条件変数(MONTH)の定義
[2]
条件名(SPRING、SUMMER、FALLおよびWINTER)の定義
- 条件変数MONTHの値を検査するために、条件名条件を使って以下のIF文を書くことができる。
[1] IF SPRING … → IF MONTH >= 3 AND <= 5 と等価
[2] IF SUMMER
… → IF MONTH >= 6 AND <= 8 と等価
[3] IF FALL … → IF MONTH >= 9
AND <= 11 と等価
[4] IF WINTER … → IF MONTH = 12 OR 1 OR 2
と等価
(4) スイッチ状態条件
スイッチ状態条件は、外部スイッチのオンとオフの状態を調べるために使う。
書き方
条件名-1
- 外部スイッチは環境部の特殊名段落で定義し、そのオン状態またはオフ状態に条件名を対応付けなければならない。
- 外部スイッチが条件名-1の状態に設定されている場合、スイッチ状態条件が真となる。
(※) SIT COBOLはスイッチ状態条件は未サポートである。(サポート予定あり)
(5) 正負条件
正負条件は、算術式の代数値がゼロより大きいか、小さいかまたは等しいかを調べるために使う。
書き方
算術式-1 IS [ NOT ] { POSITIVE | NEGATIVE | ZERO }
- 算術式-1には、少なくとも1つの一意名を書かなければならない。
- 正負条件では、算術式の代数値を検査し、POSITIVE、NEGATIVEまたはZEROの指定に従って、真理値を決定する。これらの必要語の意味を、下表に示す。
| 必要語 | 意味 |
| POSITIVE | ゼロより大きい |
| NEGATIVE | ゼロより小さい |
| ZERO | ゼロに等しい |
- NOTを書いた場合、NOTと必要語で1つの正負条件になる。NOTを書くと、真理値の真/偽がNOTを書かなかった場合の逆になる。例えば、“NOT ZERO”は、算術式の値がゼロでないとき(正または負のとき)真になる。
(6) 複合条件
複合条件は、単純条件と論理演算子を組み合わせて書く。
複合条件は、否定条件と組合せ条件で構成する。否定条件は、単純条件または複合条件の前に、論理演算子NOTを書いたものである。組合せ条件は、単純条件または複合条件を、論理演算子ANDまたはORでつないだものである。
複合条件の真理値は、個々の条件の真理値を評価し、すべての論理演算子を順に作用させた結果の真理値である。
論理演算子の意味を、下表に示す。
| 論理演算子 | 意味 | 真理値 |
| NOT | 論理否定 |
NOT の後の条件が偽の場合、真理値は真。 NOT の後の条件が真の場合、真理値は偽。 |
| AND | 論理積 |
AND の左辺と右辺の両方の条件が真の場合、真理値は真。 AND の左辺と右辺の一方または両方の条件が偽の場合、真理値は偽。 |
| OR | 論理和 |
ORの左辺と右辺の一方または両方の条件が真の場合、真理値は真。 ORの左辺と右辺の両方の条件が偽の場合、真理値は偽。 |
否定条件
否定条件は、条件の真理値を逆転するために使う。
書き方
NOT 条件-1
組合せ条件
組合せ条件は、論理積または論理和を求めるために使う。
書き方
条件-1 { { AND | OR } 条件-2 } …
複合条件の書き方の規則
- 複合条件で許される単純条件、論理演算子および括弧の組合せを、下表に示す。
| — | 後続する要素 | |||||
| 先行する要素 | 単純条件 | AND | OR | NOT | ( | ) |
| 単純条件 | — | ○ | ○ | — | — | ○ |
| AND | ○ | — | — | ○ | ○ | — |
| OR | ○ | — | — | ○ | ○ | — |
| NOT | ○ | — | — | — | ○ | — |
| ( | ○ | — | — | ○ | ○ | — |
| ) | — | ○ | ○ | — | — | ○ |
- 複合条件は、単純条件、NOTまたは“(”で始まり、単純条件または“)”で終わらなければならない。
- 論理演算子の前後には、空白を置かなければならない。ただし、論理演算子と括弧の間の空白は、省略することができる。
- 左括弧と右括弧は一対一に対応付け、左括弧を右括弧より前に書かなければならない。
複合条件の評価規則
- 複合条件の評価順序は、括弧を使って指定することができる。括弧を書かないときの論理演算子の評価順序は、以下のとおりである。
- 1番目: NOT
- 2番目: AND
- 3番目: OR
- 論理演算子の評価順序を変更したい場合、論理演算子による条件の結合範囲を括弧で囲む。括弧を書くと、論理演算子によって結合された条件および括弧の中の論理演算子が、先に評価される。括弧が入れ子になっている場合は、一番内側の括弧の中の条件と論理演算子が最初に評価され、順次外側が評価される。
- 同じ順位の論理演算子が続いている場合、論理演算子は左から右の順に評価される。
- 複合条件の中の個々の条件の評価は、すべての条件が評価されているかどうかに関係なく、複合条件の真理値が決まったときに終了する。
- 複合条件の中の算術式の値および関数値は、それらを書いた条件が評価されるときに決まる。
- 否定条件は、論理演算子NOTと連結された条件が評価されるときに評価される。
複合条件の評価順序の例
“条件-1 AND 条件-2 AND … 条件-n”の評価は、条件-1, 条件-2を順に評価していき、偽となった時点で真偽値は偽として評価を完了する。最後の条件-nまで真であった場合は真偽値は真となる。
“条件-1 OR 条件-2 OR … 条件-n”の評価は、条件-1, 条件-2を順に評価していき、真となった時点で真偽値は真として評価を完了する。最後の条件-nまで偽であった場合は真偽値は偽となる。
“条件-1 OR 条件-2 AND 条件-3”の評価順序は、条件-1が真の場合は真偽値は真として評価を完了する。条件-1が偽だった場合は、条件-2を評価し偽の場合は真偽値は偽として評価を完了する。条件-2が真だった場合は、続けて条件-3を評価し、真だったときは真偽値を真、偽だったときは真偽値を偽として評価を完了する。
“(条件-1 OR NOT 条件-2) AND 条件-3 AND 条件-4” の評価は、まず括弧内の真偽値を評価し偽だった場合は真偽値が偽として評価を完了する。真だった場合は、条件-3の評価を行う。以下、同様である。
(7) 組合せ比較の略記法
比較条件と論理演算子を組み合わせた複合条件を、「組合せ比較条件」という。組合せ比較条件の中に、論理演算子の評価順序を変更するための括弧がない場合、組合せ条件の一部を省略して書くことができる。
組合せ条件の省略方法として、以下の2つがある。
- 後続の比較条件の左辺が直前のものと同じ場合、後続の比較条件の左辺を省略することができる。
- 後続の比較条件の左辺と比較演算子の両方が直前のものと同じ場合、後続の比較条件の左辺と比較演算子の両方を省略することができる。
書き方
比較条件 {{ AND | OR } [ NOT ] [ 比較演算子 ]右辺 } …
- 一連の比較条件の中で、2つの省略方法の両方を使うことができる。
- 省略した左辺には、その直前に書いた左辺が補われる。省略した比較演算子には、その直前に書いた比較演算子が補われる。省略した左辺と比較演算子の補充は、複合条件の中で略記されていない単純条件が現れるまで繰り返される。左辺と比較演算子が補われた結果は、“複合条件”で説明した規則に従っていなければならない。
- 略記した組合せ比較条件の中にNOTを書いた場合、NOTは以下のように解釈される。
- NOTの直後にGREATER、>、LESS、<、EQUAL、=のいずれかが続く場合、NOTはその比較演算子の一部であるとみなされる。
- a.以外のNOTは、論理演算子であるとみなされる。したがって、省略した左辺と比較演算子が補われた結果は、否定条件になる。
- 略記した組合せ比較条件の例を、下表に示す。
| 組合せ比較条件を略記した書き方 | 組合せ比較条件を略記しない書き方 |
| a > b AND NOT < c OR d | ((a > b) AND (a NOT < c)) OR (a NOT < d) |
| a NOT EQUAL b OR c | (a NOT EQUAL b) OR (a NOT EQUAL c) |
| NOT a = b OR c | (NOT (a = b)) OR (a = c) |
| NOT (a GREATER b OR < c) | NOT ((a GREATER b) OR (a < c)) |
| NOT (a NOT > b AND c AND NOT d) | NOT (((a NOT > b) AND (a NOT > c)) AND(NOT (a NOT > d))) |
6.4.3 比較の規則
ここでは、比較条件の比較の規則について説明する。比較では、比較条件の左辺と右辺の組合せによって、以下のいずれかの規則が適用される。
- 文字比較
- 数字比較
- 日本語文字比較
- 指標比較
文字比較、数字比較および日本語文字比較の規則が適用される場合の作用対象の組合せは、下表のとおりである。
| — | 条件の左辺(右辺) | ||||||
| 条件の右辺(左辺) | 集団 |
英字 英数字(*1) 英数字編集 数字編集 |
日本語 日本語編集 |
外部10進 |
2進 内部10進 |
算術式(*2) | |
| 集団項目 | 文字比較 | 文字比較 | 文字比較 | 文字比較 | 文字比較 | — | |
|
英字項目 英数字項目(*1) 英数字編集項目 数字編集項目 文字定数(*3) |
文字比較 | 文字比較 | — | 文字比較 | — | — | |
|
日本語項目(*4) 日本語編集項目 日本語定数(*5) |
文字比較 | — | 日本語文字比較 | 文字比較 | — | — | |
|
表意定数 SPACE |
文字比較 | 文字比較 | 日本語文字比較 | 文字比較 | — | — | |
|
表意定数 HIGH-VALUE LOW-VALUE QUOTE |
文字比較 | 文字比較 | — | 文字比較 | — | — | |
|
表意定数 ZERO |
文字比較 | 文字比較 | — | 数字比較 | 数字比較 | 数字比較 | |
| 外部10進項目 | 文字比較 | 文字比較 | — | 数字比較 | 数字比較 | 数字比較 | |
|
2進数 内部10進数 |
文字比較 | — | — | 数字比較 | 数字比較 | 数字比較 | |
| 数字定数 | 文字比較 | 文字比較(*6) | — | 数字比較 | 数字比較 | 数字比較 | |
| 算術式(*2) | — | — | — | 数字比較 | 数字比較 | 数字比較 | |
(*1): 英数字項目は、英数字関数を含む
(*2): 算術式は、数字関数、整数関数を含む
(*3): 文字定数は、ALL文字定数を含む
(*4): 日本語項目は、日本語関数を含む
(*5): 日本語定数は、ALL 日本語定数を含む
(*6): 英数字関数と数字関数を比較することはできない
(1) 文字比較
文字比較の規則は、以下のとおりである。
- 2つの作用対象が、文字の大小順序に従って比較される。
- 2つの作用対象の文字位置の個数が等しい場合、対応する文字位置の文字が、最左端から最右端に向かって一組ずつ順に比較される。比較の結果は、以下のように決定される。
- 対応する文字がすべて等しい場合、2つの作用対象は等しいという結果になる。
- 対応する文字が等しくない組が最初に現れたとき、文字の大小順序で高い位置の文字を含む作用対象の方が大きいという結果になる。
- 2つの作用対象の文字位置の個数が異なる場合、短い方の作用対象の右側には、長い方の作用対象の文字位置の個数と同じになるまで空白があるものとみなされる。比較の方法は、2.と同じである。
- 数字作用対象(外部10進項目、2進項目、内部10進項目、数字定数、表意定数ZERO)を文字作用対象(集団項目、英字項目、英数字項目、英数字編集項目、数字編集項目、文字定数、日本語項目、日本語編集項目、日本語定数、表意定数SPACE、HIGH-VALUE、LOW-VALUE、QUOTEまたは記号文字)と比較する場合、以下の規則が適用される。
- 数字作用対象は整数でなければならない。
- 文字作用対象が基本項目または文字定数の場合、数字作用対象が文字作用対象と同じ大きさの英数字項目に転記したかのように扱われる。この英数字項目が文字作用対象と比較される。
- 文字作用対象が集団項目の場合、まず数字作用対象が文字作用対象と同じ大きさの集団項目に転記したかのように扱われる。次に、この集団項目が文字作用対象と比較される。
- 作用対象のどちらかが強く型付けされた集団項目である場合、もう一方の作用対象は同じ型で強く型付けられた集団項目でなければならない。
- 文字の大小順序については“PROGRAM COLLATING SEQUENCE句”を参照のこと。
(2) 数字比較
数字比較の規則は以下のとおりである。
- 2つの作用対象が代数的な値に基づいて比較される。
- 値ゼロは、符号の有無に関係なくゼロとして比較される。
- 符号のない作用対象は、その符号部が正であるとみなされて比較される。
(3) 日本語文字比較
日本語文字比較の規則は、以下のとおりである。
- 2つの作用対象が、日本語文字の大小順序に従って比較される。
- 2つの作用対象の日本語文字位置の個数が等しい場合、対応する日本語文字位置の日本語文字が、最左端から最右端に向かって一組ずつ順に比較される。比較の結果は、以下のように決定される。
- 対応する日本語文字がすべて等しい場合、2つの作用対象は等しいという結果になる。
- 対応する日本語文字が等しくない組が最初に現れたとき、日本語文字の大小順序で高い位置の日本語文字を含む作用対象の方が大きいという結果になる。
- 2つの作用対象の日本語文字位置の個数が異なる場合、短い方の作用対象の右側には、長い方の作用対象の日本語文字位置の個数と同じになるまで日本語空白があるものとみなされる。比較の方法は2.と同じである。
(4) 指標比較
指標比較の規則を、下表に示す。
| — | 条件の右辺(左辺) | |||
| 条件の右辺(左辺) | 指標名 | 指標データ項目 |
数字定数 (整数だけ) |
数字項目 (整数だけ) |
| 指標名 | 出現番号の比較 | 変換なしの比較 | 出現番号と整数の比較 | 出現番号と整数の比較 |
| 指標データ項目 | 変換なしの比較 | 変換なしの比較 | — | — |
出現番号の比較: 指標名に対する出現番号どうしが比較される。
出現番号と整数の比較: 指標名に対応する出現番号が、田の作用対象と比較される。
変換なしの比較:実際の値がそのまま比較される。
6.4.4 転記の規則
ここでは、MOVE文の転記の規則を説明する。
文の実行によって、データ項目、定数または算術演算の結果がデータ項目に転記されることがある。転記の規則は、明に書いたMOVE文だけでなく、このような暗黙のMOVE文でも適用される。
転記の規則には、基本項目転記と集団項目転記がある。送出し側と受取り側のいずれか一方または両方が集団項目の場合、集団項目転記の規則が適用される。そうでない場合、基本項目転記の規則が適用される。
(1) 基本項目転記
基本項目転記では、受取り側の項類および用途によって、以下のいずれかの規則が適用される。
- 英字転記
- 英数字・英数字編集転記
- 数字・数字編集転記
- 日本語・日本語編集転記
基本項目転記では、必要ならば、内部表現形式の変換、編集または逆編集が行われる。基本項目転記の作用対象の組合せを、下表に示す。
| — | 受取り側 | |||
| 送出し側 | 英字 |
英数字 英数字編集 |
数字 数字編集 |
日本語 日本語編集 |
| 英字項目 | [1] | [2] | — | [5] |
|
英数字項目(*1) 文字定数(*2) |
[1] | [2] | [3] | [5] |
| 英数字編集項目 | [1] | [2] | — | [5] |
|
数字項目/定数 (整数) |
— | [2] | [3] | [5] |
|
数字項目/定数 (非整数) |
— | — | [3] | — |
| 数字編集項目 | — | [2] | [3] | [5] |
|
日本語項目(*3) 日本語編集項目 日本語定数(*4) |
— | — | — | [4] |
|
表意定数 ZERO |
— | [2] | [3] | [5] |
|
表意定数 SPACE |
[1] | [2] | — | [5] |
|
表意定数 HIGH-VALUE LOW-VALULE |
— | [2] | — | — |
|
表意定数 QUOTE |
— | [2] | — | — |
—: 転記できない組合せ
(*1): 英数字項目は、英数字関数を含む
(*2): 文字定数は、ALL文字定数を含む
(*3): 日本語項目は、日本語関数を含む
(*4): 日本語定数は、ALL 日本語定数を含む
(※) SIT COBOLは、[5]に関する基本項目転記を行うことができる。
英字転記:[1]
受取り側が英字項目の場合、標準桁よせ規則に従って、桁よせおよび必要な空白づめが行われる。
英数字・英数字編集転記:[2]
受取り側が英数字項目または英数字編集項目の場合、以下の規則が適用される。
- 標準桁よせ規則に従って、桁よせおよび必要な空白づめが行われる。
- 送出し側が符号付き数字項目の場合、符号は転記されない。送出し側項目のSIGN句にSEPARATE指定を書いた場合、符号は転記されないので、送出し側の桁数が編集データ形式で1桁小さいものとして転記される。
- 送出し側が数字編集項目の場合、逆編集(編集文字の除去)は行われない。
- 送出し側の用途が受取り側の用途と異なる場合、送出し側が受取り側の内部表現に変換される。
- 送出し側が数字項目でPICTURE句に“P”を含む場合、“P”が示す桁位置はゼロであるとみなされる。“P”は送出し側の大きさに数える。
数字・数字編集転記:[3]
受取り側が数字項目または数字編集項目の場合、以下の規則が適用される。
- 標準桁よせ規則に従って、小数点の位置合わせおよび必要なゼロづめが行われる。そのゼロは、PICTURE句の記述に従って、他の文字に変換されることがある。
- 送出し側が数字編集項目の場合、まず逆編集が行われ、編集される前の符号のない数値が求められる。その編集される前の数値が、受取り側に転記される。
- 受取り側が符号付き数字項目の場合、受取り側には送出し側の符号と同じ符号が付けられる。このとき、必要ならば符号の表現形式が変換される。送出し側に符号がない場合は、受取り側に正の符号が付けられる。
- 受取り側が符号なし数字項目の場合、送出し側の絶対値が転記される。受取り側には符号は付けられない。
- 送出し側の項類が英数字の場合、送出し側のデータは符号なし整数とみなされて転記される。
- 送出し側が浮動小数点項目かつ保持する値が受取り側より大きな小数部の桁数を持つ場合、受取り側の小数部の桁数+1の位で四捨五入した値が転記される。
日本語・日本語編集転記:[4]
受取り側が日本語項目または日本語編集項目の場合、標準桁よせ規則に従って、桁よせおよび必要な空白づめが行われる。
半角から全角変換転記:[5]
送出し側が英字項目、英数字項目、文字定数および英数字編集項目の場合、送出し側の半角文字が、全角文字となって受取り側に転記される。
(例) 「MOVE “ABC” TO N3.」(N3はPIC N(3)で定義)においては、N3には、“ABC” が転記される。
送出し側が数字項目、数字定数、数字編集項目の場合は、次のように転記される。
- 標準桁よせ規則に従って、小数点の位置合わせおよび必要なゼロづめが行われる。
- 半角数字に対応する全角数字となって受取り側に転記される。
- 符号があっても取り除かれる。
(例) 「MOVE 123 TO N5.」(N5はPIC N(5)で定義)においては、N5には、“00123” が転記される。
送出し側が表意定数のZERO、SPACEの場合は、ALL指定があるとみなされ、それぞれ全角の”0”, 空白に変換されて受取り側に転記される。
集団項目転記
送出し側または受取り側のどちらか一方または両方が集団項目の場合、以下の規則が適用される。
- 集団項目転記は、英数字項目どうしの基本項目転記と同様に行われる。
- 内部表現形式の変換は行われない。
- 集団項目に従属する個々の基本項目と集団項目は考慮されない。集団項目全体が1つの英数字項目であるかのように転記される。ただし、集団項目または集団項目に従属するデータ項目にOCCURS句を指定した場合は、別の規則が適用される」。OCCURS句を含む集団項目の転記の規則については、“OCCURS句”を参照のこと。
6.4.5 算術文
ADD文、COMPUTE文、DIVIDE文、MULTIPLY文およびSUBTRACT文の5つを総称して、「算術文」という。算術文に共通する規則は、以下のとおりである。
- 算術文の作用対象のデータ記述項は、同一である必要はない。計算の過程において、必要な変換と小数点の位置合わせが行われる。
- 算術演算の過程で、一時的な演算結果を格納するためのデータ項目が必要になることがある。この一時的なデータ項目を「中間結果」という。中間結果のための記憶領域は、符号付き数字項目として、SIT COBOLによって用意される。中間結果の桁数は、“中間結果”で説明する算法に従って決定される。実行時、中間結果に一時的に格納された演算結果は、MOVE文の規則に従って、結果を格納するためのデータ項目に転記される。
6.4.6 算術文における複数の答
算術文には、結果の一意名(結果を格納するためのデータ項目)を2つ以上書くことができる。
この場合、算術文の結果は以下の順に計算される。
- 文の初期評価の対象となっているすべてのデータ項目に対して、必要な計算が行われる。そして、その結果が一時的なデータ項目に格納される。
- 次に、結果の一意名の1つ1つに対して、1.で求めた一時的なデータ項目との計算が行われ、結果が格納される。この計算は、結果の一意名を指定した順に、左から右に行われる。
複数個の答を計算する例を、以下に示す。tempは、コンパイラが用意した一時的な記憶領域を表す。
〔例1〕
000000 ADD a b c TO c d(c) e上記の計算のしかたは、以下の文を順に実行した場合と同じである。
000000 ADD a b c GIVING temp
000000 ADD temp TO c
000000 ADD temp TO d(c) ... c の値は、直前の加算で変更された値。
000000 ADD temp TO e〔例2〕
000000 MULTIPLY a(i) BY i a(i)上記の計算のしかたは、以下の文を順に実行した場合と同じである。
000000 MOVE a(i) TO temp
000000 MULTIPLY temp BY i
000000 MULTIPLY temp BY a(i) ... i の値は、直前の乗算で変更された値。6.4.7 ROUNDED指定
算術文には、ROUNDED指定を書くことができる。
算術演算の結果の小数部の桁数が、結果の一意名の小数部の桁数より大きい場合、ROUNDED指定の有無に従って、以下の処理が行われる。
- ROUNDED指定を書かなかった場合、算術演算の結果の小数部が、結果の一意名の桁数に合わせて切り捨てられる。
- ROUNDED指定を書いた場合、切捨て部分の最上位の桁の値が5以上のとき、結果の一意名の最下位の桁の絶対値が1増やされる。
結果の一意名の整数部の下位桁をPICTURE句の文字“P”で定義した場合、四捨五入および切捨ては、実際に記憶領域を割り当てられている部分の、最右端の整数部に対して行われる。
6.4.8 ON SIZE ERROR指定
算術文を実行すると、桁あふれ条件が発生することがある。桁あふれ条件は、算術文にON SIZE ERROR指定を書くことによって検出することができる。
桁あふれ条件が発生する条件
桁あふれ条件は、以下の場合に発生する。
- べき乗の底の値がゼロで、かつその指数の値がゼロ以下の場合。
- べき乗の評価の結果が実数でない場合。
- 除算の除数がゼロの場合。
- 演算結果の絶対値が、結果の一意名に格納できる最大の値を超えた場合。ただし結果の一意名が単精度/倍精度2進数の場合、演算結果が単精度/倍精度2進数の値の範囲に収まらない場合。
4.で、結果の一意名に格納できる最大の値とは、PICTURE句の文字列で指定した最大の値である。
結果の一意名が2進項目の場合も、記憶領域に格納できる最大の値ではなく、PICTURE句の文字列で指定した最大の値である。なお、演算結果が、結果の一意名より小数点以下の桁を多く持つ場合、演算結果と同じだけの小数点以下の桁を持つPICTURE句の文字列で指定した最大の値を、結果の一意名に格納できる最大の値とみなす。また、結果の一意名が“P”を含むPICTURE句で定義されている場合、“P”を“9”で置き換えたPICTURE句の文字列で指定した最大の値を、結果の一意名に格納できる最大の値とみなす。
4.の桁あふれ条件は、1つの算術演算の最終結果に格納するときにだけ発生し、中間結果に格納するときは発生しない。ROUNDED指定を書いた場合、四捨五入が行われた後、4.の桁あふれ条件が検査される。
結果の一意名を2つ以上書いた場合、それぞれの算術演算の結果を求めるときに、それぞれ桁あふれ条件が検査される。
桁あふれ条件が発生したときの動作
桁あふれ条件が発生すると、結果の一意名の値は、以下の値になる。
- ON SIZE ERROR指定またはNOT ON SIZE ERROR指定を書いた場合、桁あふれ条件が発生した一意名の値は、算術文の実行前のまま変更されない。
- ON SIZE ERROR指定もNOT ON SIZE ERROR指定も書かなかった場合、桁あふれ条件が発生した一意名の値は、規定されない。
- 桁あふれ条件が発生しなかった一意名には、ON SIZE ERROR指定とNOT ON SIZE ERROR指定の有無に関係なく、算術演算の結果が格納される。
算術演算の完了後、すなわち結果の一意名のすべての値が決まった後、以下の規則に従って制御が移る。
- ON SIZE ERROR指定を書いた場合、ON SIZE ERROR指定の無条件文に制御が移る。無条件文の実行後、算術文の最後に制御が移る。ただし、無条件文で制御の明示移行を起こす手続き分岐文または条件文を実行した場合、その文の規則に従って制御が移る。
- ON SIZE ERROR指定を書かなかった場合、算術文の最後に制御が移る。
桁あふれ条件が発生しなかったときの動作
桁あふれ条件が発生しなかったとき、算術演算の完了後、以下の規則に従って制御が移る。
- NOT ON SIZE ERROR指定を書いた場合、NOT ON SIZE ERROR指定の無条件文に制御が移る。無条件文の実行後、算術文の最後に制御が移る。ただし、無条件文で制御の明示移行を起こす手続き分岐文または条件文を実行した場合、その文の規則に従って制御が移る。
- NOT ON SIZE ERROR指定を書かなかった場合、算術文の最後に制御が移る。
6.4.9 CORRESPONDING指定
MOVE文、ADD文およびSUBTRACT文には、CORRESPONDING指定を書くことができる。CORRESPONDING指定は、集団項目に従属するデータ項目で同じデータ名を持つものどうしを対応付ける。CORRESPONDING指定を“CORRESPONDING d1 TO d2”のように書く場合、d1、d2および対応付けるデータ項目は、以下の条件を満足しなければならない。
- d1およびd2は、集団項目でなければならない。d1およびd2に、レベル番号が66、77または88のデータ項目を指定することはできない。
- d1およびd2に、USAGE IS INDEX句を指定したデータ項目を指定することはできない。
- d1およびd2は、部分参照することはできない。
- 対応付けるデータ項目の名前は、それらに暗黙の修飾語を付加することによって一意にならなければならない。
- MOVE文の場合、対応付けるデータ項目の少なくとも一方は基本項目でなければならない。また、対応付けるデータ項目の組合せは、転記の規則に従うものでなければならない。
- ADD文およびSUBTRACT文の場合、対応付けるデータ項目は共に数字項目でなければならない。
“CORRESPONDING d1 TO d2”を書いた場合、d1に従属するデータ項目とd2に従属するデータ項目のうち、以下のすべての条件を満足するデータ項目どうしが対応付けられる。
- データ名が同じである。ただし、FILLER項目を除く。
- d1およびd2のそれぞれ直前までの修飾語の名前の系列が同じである。
- REDEFINES句、RENAMES句、OCCURS句またはUSAGE IS INDEX句を指定していない。また、REDEFINES句、RENAMES句、OCCURS句またはUSAGE IS INDEX句を指定したデータ項目に従属していない。
6.4.10 作用対象の重なり
異なるデータ記述項で定義したデータ項目を、1つの文の送出し側項目と受取り側項目に指定した場合、それらが記憶領域の一部または全部を共有するときは、その文の実行結果は規定されない。また、同じデータ記述項で定義したデータ項目を、1つの文の送出し側項目と受取り側項目に指定した場合、その文の実行結果は規定されないことがある。この場合の規則は、各文の一般規則で説明する。
6.4.11 INVALID KEY指定
相対ファイルまたは索引ファイルに対して、DELETE文、乱呼出しのREAD文、REWRITE文、START文またはWRITE文を実行すると、無効キー条件が発生することがある。無効キー条件は、これらの入出力文にINVALID KEY指定を書くことによって検出することができる。また、無効キー条件が発生せずに入出力文の実行が成功したことを、NOT INVALID KEY指定を書くことによって検査することができる。ここでは、無効キー条件が発生する可能性のある入出力文の動作を、以下の3つに分類して説明する。
- 無効キー条件が発生したときの動作
- 無効キー条件以外の例外条件が発生したときの動作
- 無効キー条件もその他の例外条件も発生しなかったときの動作
無効キー条件が発生したときの動作
無効キー条件が発生すると、入出力文の実行は不成功に終わる。入出力状態に無効キー条件を示す値が設定された後、入出力文のINVALID KEY指定の有無、および関連するUSE AFTER STANDARD EXCEPTION手続きの有無に従って、制御が移る。無効キー条件が発生したときの制御の移行を、下表に示す。
| INVALID KEY指定の有無 | USE AFTER STANDARD EXCEPTION手続きの有無 | 無効キー条件が発生したときの制御の移行 |
| あり | あり、または、なし |
[1] ファイルにFILE
STATUS句が指定されている場合は入出力状態の値が設定される。 [2] INVALID KEY指定の無条件文に制御が移る。 [3] 無条件文の実行後、入出力文の最後に制御が移る。(*1) |
| なし | あり |
[1] ファイルにFILE
STATUS句が指定されている場合は、入出力状態の値が設定される。 [2] USE手続きが実行される。 [3] 入出力文の最後に制御が移る。 |
| なし | なし |
ファイルにFILE
STATUS句が指定されている場合は入出力状態の値が設定され、入出力文の最後に制御が移る。 ファイルにFILE STATUS句が指定されていなかった場合、実行結果は規定されない。(*2) |
(*2): SIT COBOLは、エラーメッセージを表示し、入出力文の最後に制御が移る。
無効キー条件以外の例外条件が発生したときの動作
無効キー条件以外の例外条件が発生すると、入出力文の実行は不成功に終わる。入出力状態に例外条件を示す値が設定された後、以下に示す規則に従って制御が移る。
- 関連するUSE AFTER STANDARD EXCEPTION手続きを書いた場合、USE AFTER STANDARD EXCEPTION手続きに制御が移る。そして、USE文の規則に従って、制御が移る。
- 関連するUSE AFTER STANDARD EXCEPTION手続きを書かなかった場合、ファイルにFILE STATUS句を指定したときは、入出力文の最後に制御が移る。FILE STATUS句を指定しなかったときは、実行結果は規定されない。(*1)
(*1): SIT COBOLは、エラーメッセージを表示し、入出力文の最後に制御が移る。
無効キー条件もその他の例外条件も発生しなかったときの動作
無効キー条件もその他の例外条件も発生しなかったとき、入出力文の実行は成功する。入出力状態にその旨を示す値が設定された後、以下に示す規則に従って制御が移る。
- 入出力文にNOT INVALID KEY指定を書いた場合、NOT INVALID KEY 指定の無条件文に制御が移る。そして、無条件文の実行後、入出力文の最後に制御が移る。ただし、無条件文で制御の明示移行を起こす手続き分岐文または条件文を実行した場合、その文の規則に従って制御が移る。
- 入出力文にNOT INVALID KEY指定を書かなかった場合、入出力文の最後に制御が移る。
6.4.12 AT END指定
順ファイル、相対ファイルまたは索引ファイルに対して順呼出しのREAD文を実行すると、ファイル終了条件が発生することがある。ファイル終了条件は、READ文にAT
END指定を書くことによって検出することができる。また、ファイル終了条件が発生せずに入出力文の実行が成功したことを、NOT
AT END指定を書くことによって検査することができる。
ここでは、READ文の動作を、以下の3つに分類して説明する。
- ファイル終了条件が発生したときの動作
- ファイル終了条件以外の例外条件が発生したときの動作
- ファイル終了条件もその他の例外条件も発生しなかったときの動作
ファイル終了条件が発生したときの動作
ファイル終了条件が発生すると、READ文の実行は不成功に終わる。入出力状態にファイル終了条件を示す値が設定された後、READ文のAT END指定の有無、および関連するUSE AFTER STANDARD EXCEPTION手続きの有無に従って、制御が移る。ファイル終了条件が発生したときの制御の移行を、下表に示す。
| AT END指定の有無 | USE AFTER STANDARD EXCEPTION手続きの有無 | ファイル終了条件が発生したときの制御の移行 |
| あり | あり または、なし |
[1] ファイルにFILE
STATUS句が指定されている場合は、入手力状態を設定する。 [2] AT END指定の無条件文に制御が移る。 [3] 無条件文の実行後、READ文の最後に制御が移る。(*1) |
| なし | あり |
[1] ファイルにFILE
STATUS句が指定されている場合は、入手力状態を設定する [2] USE AFTER STANDARD EXCEPTION手続きに制御が移る。 [3] USE AFTER STANDARD EXCEPTION手続きの実行後、READ文の最後に制御が移る。 |
| なし | なし |
ファイルにFILE STATUS
句が指定されている場合、入出力状態を設定し、READ文の最後に制御が移る。 ファイルにFILE STATUS 句が指定されていない場合、実行結果は規定されない。(*2) |
(*2): SIT COBOLは、エラーメッセージを表示し、入出力文の最後に制御が移る。
ファイル終了条件以外の例外条件が発生したときの動作
ファイル終了条件以外の例外条件が発生すると、READ文の実行は不成功に終わる。入出力状態に例外条件を示す値が設定された後、以下に示す規則に従って制御が移る。
- 関連するUSE AFTER STANDARD EXCEPTION手続きを書いた場合、USE AFTER STANDARD EXCEPTION手続きに制御が移る。そして、USE文の規則に従って、制御が移る。
- 関連するUSE AFTER STANDARD EXCEPTION手続きを書かなかった場合、ファイルにFILE STATUS句を指定したときは、READ文の最後に制御が移る。FILE STATUS句を指定しなかったときは、実行結果は規定されない。(*1)
(*2) SIT COBOLは、エラーメッセージを表示し、入出力文の最後に制御が移る。
ファイル終了条件もその他の例外条件も発生しなかったときの動作
ファイル終了条件もその他の例外条件も発生しなかったとき、READ文の実行は成功する。入出力状態にその旨を示す値が設定された後、以下に示す規則に従って制御が移る。
- READ文にNOT AT END指定を書いた場合、NOT AT END指定の無条件文に制御が移る。そして、無条件文の実行後、READ文の最後に制御が移る。ただし、無条件文で制御の明示移行を起こす手続き分岐文または条件文を実行した場合、その文の規則に従って制御が移る。
- READ文にNOT AT END指定を書かなかった場合、READ文の最後に制御が移る。
6.4.13 矛盾するデータ
字類条件を除いて、手続き部でデータ項目の内容が参照されるとき、データ項目の内容がPICTURE句によるデータ項目の字類または関数による字類と矛盾する場合、手続き部での参照の結果は規定しない。(*1)
(*1) SIT COBOLは、エラーメッセージを出力し、処理を続行する。
6.5 中核の文
この節では、中核の各文について説明する。
6.5.1 ACCEPT文(小入出力)
一般形式
書き方1
ACCEPT 一意名-1 [ FROM 呼び名 ]
書き方2
ACCEPT 一意名-2 FROM { DATE | DAY | DAY-OF-WEEK | TIME }
書き方3
ACCEPT 一意名-3 FROM { ENVIRONMENT-VALUE | ENVIRONMENT { 定数-1 | 一意名-4 }}
機能
書き方1
コンソールより値を読み込み、一意名-1に格納する。
- FROM 指定を使う場合、指定する呼び名は SYSIN または CONSOLE のいずれかである必要がある。SYSIN と CONSOLE は同じ意味を持つものとして使われ、どちらもコンソールを参照する。
- FROM 指定がない場合は、FROM CONSOLE が指定されたとみなす。
- コンソールからの入力値は、“MOVE 入力値 TO 一意名-1” が実行されたかのように一意名-1に設定される。ここで、入力値は数字(小数点や符号を含む)の場合は数字定数、そうでない場合は文字定数として扱われる。
書き方例
000000 01 氏名 PIC X(20).
000000 01 年齢 PIC 9(2).
000000 :
000000 ACCEPT 氏名. *> コンソールから入力された文字列が文字として「氏名」に格納される
000000 ACCEPT 年齢. *> コンソールから入力された文字列が数字として「年齢」に格納される書き方2
システムの現在の日付や時刻を取得して一意名-2に格納する。
- DATEを指定すると、西暦年月日YYMMDD(6桁の数字)を取得する。
- DAYを指定すると、西暦年および通算日数YYDDD(5桁の数字)を取得する。DDDは、1月1日から取得日YYMMDDまでの通算日数である。例えば、2024年2月1日は、2024年1月1日から数えて32日目なので、DDDは032となる。
- DAY-OF-WEEKを指定すると、曜日N(1桁の数字)を取得する。Nはそれぞれ、月曜日:1, 火曜日:2, 水曜日:3, 木曜日:4, 金曜日:5, 土曜日:6, 日曜日:7 である。
- TIMEを指定すると、時分秒および1/100秒HHMMSSmm(8桁の数字)を取得する。
書き方例
000000 01 年月日 PIC 9(6)
000000 :
000000 ACCEPT 年月日 FROM DATE. *> 取得日が2024年12月28日の場合、「年月日」には
000000 *> 241228が格納される書き方3
環境変数を取得する
- ENVIRONMENT-VALUEを指定した場合、特殊レジスタENVIRONMENT-NAME(PIC X(128)で定義されている)に設定されている環境変数名の値を取得し一意名-3に設定する。
- ENVIRONMENTを指定した場合、定数-1 または 一意名-4 に設定されている環境変数名の値を取得し、一意名-3に設定する。
書き方例1
000000 01 環境変数値 PIC X(10).
000000 :
000000 MOVE "XYZ" TO ENVIRONMENT-NAME.
000000 ACCEPT 環境変数値 FROM ENVIRONMENT-VALUE. *> '環境変数値'に、環境変数XYZの値が
000000 *>設定される。書き方例2
000000 01 環境変数値 PIC X(10).
000000 :
000000 ACCEPT 環境変数値 FROM ENVIRONMENT "XYZ". *>'環境変数値'に、環境変数XYZの値が
000000 *> 設定される。(サンプルプログラム名:ACCEPT文.cob)
6.5.2 ACCEPT文(スクリーン操作)
画面からデータを入力する。
一般形式
書き方
ACCEPT データ名-1
[ ENABLE KEY IS { PFキー名-1 } … ]
[ AT { LINE NUMBER { 一意名-1 | 整数-1 } | COLUMN NUMBER { 一意名-2 | 整数-2 } } ]
構文規則
- データ名-1は、画面節で定義した画面項目でなければならない。その画面項目は、以下のいずれかでなければならない。
- PICTURE句にTO指定またはUSING指定を書いた基本画面項目
- PICTURE句にTO指定またはUSING指定を書いた基本画面項目を従属する集団画面項目
- データ名-1は、修飾することができる。
- PFキー名-1 の書き方は、PFn (nは、1-9 または、01-24)である。このときPF1~9とPF01~09は同義である。
(※) SIT COBOL は、AT LINE NUMBER句、AT COLUMN NUMBER句を指定することはできない。
一般規則
- ACCEPT文は、データ名-1の画面項目に対応する画面上の領域からデータを読み込み、読み込んだデータを、データ名-1のPICTURE句のTO指定またはUSING指定に書いたデータ項目へ転記する。データ名-1に集団画面項目を指定した場合は、その画面項目に従属するすべての入力項目および更新項目が、この操作の対象になる。画面項目からデータ項目への転記は、転記の規則に従って行われる。
- データ名-1に集団画面項目を指定した場合、以下のように動作する。
- 1回のACCEPT文の実行で、集団画面項目に従属するすべての入力項目および更新項目への入力が可能となる。
- データの入力は、画面データ記述項のLINE NUMBER句およびCOLUMN NUMBER句で指定した、画面上の位置の順に、カーソルを移動して行う。
- ACCEPT文は、入力キー([ENTER]キー)の押下によって完了する。
- ENABLE句を指定した場合には、PFキー名-1で指定したPFキー(プログラマブル・ファンクションキー)が押された場合も、ACCEPT文が終了する。
- ENABLE句に指定したPFキーが押されてACCPET文が終了した場合、CRT-STATUS特殊レジスタ(COMP-2で定義されている)の値が更新され、実際に押されたPF1~PF24キーに対してそれぞれ、1-24が設定される。
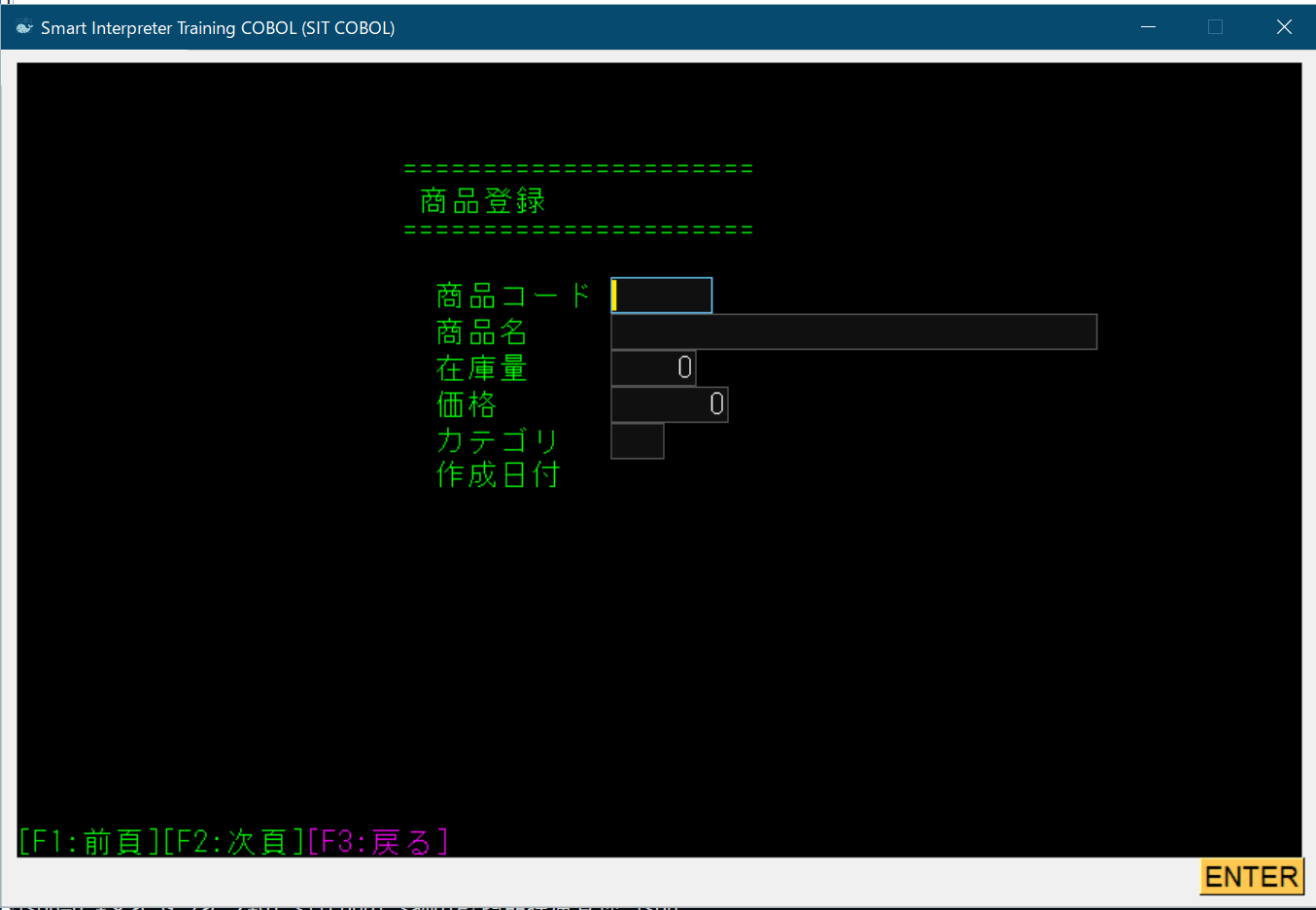
書き方例
001400 SCREEN SECTION.
:
001680*----------------------------------------------------------------
001690* 商品登録
001700*-----------------------------------------------------------------
001710 01 S商品登録画面ヘッダ BLANK SCREEN.
001720 03 LINE 4 COLUMN 25 VALUE "======================".
001730 03 LINE PLUS 1 COLUMN 25 VAlUE " 商品登録".
001740 03 LINE PLUS 1 COLUMN 25 VALUE "======================".
001750 03 LINE PLUS 2 COLUMN 25 VALUE " 商品コード".
001760 03 LINE PLUS 1 COLUMN 25 VALUE " 商品名".
001770 03 LINE PLUS 1 COLUMN 25 VALUE " 在庫量".
001780 03 LINE PLUS 1 COLUMN 25 VALUE " 価格".
001790 03 LINE PLUS 1 COLUMN 25 VALUE " カテゴリ".
001800 03 LINE PLUS 1 COLUMN 25 VALUE " 作成日付".
001810 03 LINE 25 COLUMN 25 VALUE "[F1:前頁][F2:次頁]"
001820 COLOR 緑 COLUMN 1.
001830 03 VALUE "[F3:戻る]" COLOR 紫 COLUMN PLUS 1.
001840 01 S商品登録明細入力.
001850 03 LINE 8 COLUMN 38 PIC X(6) USING W商品コード.
001860 03 LINE PLUS 1 COLUMN 38 PIC N(15) USING W商品名.
001870 03 LINE PLUS 1 COLUMN 38 PIC 9(5) USING W在庫数.
001880 03 LINE PLUS 1 COLUMN 38 PIC 9(7) USING W価格.
001890 03 LINE PLUS 1 COLUMN 38 PIC X(3) USING Wカテゴリ.
:
003540 *> 商品登録画面の表示
003550 DISPLAY S商品登録画面ヘッダ
003560 ACCEPT S商品登録明細入力 ENABLE KEY PF3
003570 *> PF3が入力されたら戻る
003580 IF CRT-STATUS = 3 GO TO 商品登録E END-IF003550行目のDISPLAY文(001710-001830行のタイトル等の表示)のあと、003560行目のACCEPT文(001840-001890行の入力項目)が実行されると下記のような画面が表示される。項目に値を設定して入力キー([ENTER]キー)を押すか、もしくはPF3キーを押したときにACCEPT文の実行が終わる。
6.5.3 ADD文
一般形式
書き方1
ADD { 一意名-1 | 定数-1 } … TO { 一意名-2 [ ROUNDED ] } …
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-ADD ]
書き方2
ADD { 一意名-1 | 定数-1 } … TO { 一意名-2 | 定数-2 } GIVING
{一意名-3 [ ROUNDED ] } …
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-ADD ]
書き方3
ADD { CORRESPONDING | CORR } 一意名-1 TO 一意名-2 [ ROUNDED ]
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-ADD ]
機能
書き方1
TOの前の各作用対象の和を一意名-2に加える。
- ROUNDED指定を書かなかった場合、算術演算の結果の小数部が、結果の一意名-2の桁数に合わせて切り捨てられる。
- ROUNDED指定を書いた場合、切捨て部分の最上位の桁の値が5以上のとき、結果の一意名-2の最下位の桁の絶対値が1増やされる。
- ON SIZE ERROR 指定は、計算結果が、一意名-2
の桁数を超えた場合に実行される文を指定する。
桁あふれが発生し、ON SIZE ERROR指定がない場合は、一意名-2には桁あふれの結果が格納される。
桁あふれが発生し、ON SIZE ERROR指定がある場合は、一意名-2 の値は変更されず、無条件文-1 が実行される。
(サンプルプログラム名:ADD文-書き方1.cob)
書き方例1
000000 01 A PIC 9(2) VALUE 10. *> Aの初期値は10
000000 01 I PIC 9(2) VALUE 1. *> Iの初期値は1
000000 01 J PIC 9(2) VALUE 2. *> Jの初期値は2
000000 :
000000 ADD 1 TO A. *> Aの結果は、A = A + 1 すなわち、11となる
000000 ADD 1 TO I J. *> I, Jの結果は、それぞれ、2, 3 となる書き方例2:ROUNDED指定の有無
000000 01 A PIC 99V9 VALUE 0.0. *> Aの小数部は1桁のみ
000000 :
000000 ADD 10.5 0.05 TO A. *> 算術結果は10.55、小数部2桁以下は切り捨てられ、
000000 *> Aには10.5が格納される
000000 ADD 10.5 0.05 TO A ROUNDED. *> 算術結果は10.55、小数部2桁で四捨五入の結果、
000000 *> Aには10.6が格納される 書き方例3:ROUNDED指定の有無(負数の場合)
000000 01 A PIC S99V9 VALUE 0.0. *> Aの小数部は1桁のみ
000000 :
000000 ADD -10.5 -0.05 TO A. *> 算術結果は-10.55、小数部2桁以下は切り捨てられ、
000000 *> Aには-10.5が格納される
000000 ADD -10.5 -0.05 TO A ROUNDED. *> 算術結果は-10.55、小数部2桁で四捨五入の結果、
000000 *> Aには-10.6が格納される 書き方例4:ON SIZE ERROR指定がある場合の桁あふれ
000000 01 A PIC 99 VALUE 99. *> Aは整数部2桁で初期値は99
000000 :
000000 ADD 1 TO A *> A = A + 1 の結果、100となるので桁あふれが発生、
000000 ON SIZE ERROR *> ON SIZE ERRORが実行される
000000 DISPLAY "桁あふれ発生" *> "桁あふれ発生"が表示される
000000 DISPLAY "A=" A *> Aの値は変わらず、"A=99"が表示される
000000 END-ADD.書き方例5:ON SIZE ERROR指定がない場合の桁あふれ
000000 01 A PIC 99 VALUE 99. *> Aは整数部2桁で初期値は99
000000 :
000000 ADD 1 TO A. *> A := A + 1 の結果、100となるので桁あふれが発生。
000000 *> しかし ON SIZE ERROR指定がないので、百の位の1は
000000 *> 無視されAには下2桁の00が設定される
000000 DISPLAY "A=" A. *> "A=0"が表示される書き方2
TOの前の各作用対象の和を、TOの後の作用対象に加え、一意名-3に格納する。
- ROUNDED指定、およびON SIZE ERROR指定については、書き方1を参照のこと。
(サンプルプログラム名:ADD文-書き方2.cob)
書き方例:
000000 01 A PIC 99 VALUE 99.
000000 01 B PIC 9(5).
000000 :
000000 ADD 1 2 TO A GIVING B. *> COMPUTE B = 1 + 2 + A と同等である。書き方3
一意名-1に従属するデータ項目と一意名-2に従属するデータ項目のうち、名前の修飾語の系列が同じものどうしの和を求める。一意名-1に従属するデータ項目を加数、一意名-2に従属するデータ項目を被加数として和を求め、一意名-2に従属するデータ項目に格納する。この結果は、対応する一意名ごとに、別々のADD文を書いた結果と同じである。
- 対応付けるデータ項目は共に数字項目でなければならない。
- “CORRESPONDING d1 TO d2”を書いた場合、d1に従属するデータ項目とd2に従属するデータ項目のうち、以下のすべての条件を満足するデータ項目どうしが対応付けられる。
- データ名が同じである。ただし、FILLER項目を除く。
- d1およびd2のそれぞれ直前までの修飾語の名前の系列が同じである。
- REDEFINES句、RENAMES句、OCCURS句またはUSAGE IS INDEX句を指定していない。また、REDEFINES句、RENAMES句、OCCURS句またはUSAGE IS INDEX句を指定したデータ項目に従属していない。
- CORRESPONDINGとCORRは同義語である。
- ROUNDED指定、およびON SIZE ERROR指定については、書き方1を参照のこと。
書き方例: CORRESPONDING指定
(サンプルプログラム名:ADD文-書き方3.cob)
000000 01 X.
000000 03 B PIC X VALUE "A".
000000 03 C.
000000 05 C1 PIC 9 VALUE 1.
000000 05 C2 PIC 9 VALUE 2.
000000 05 FILLER PIC 9 VALUE 3.
000000 03 D.
000000 05 D1 PIC 9 VALUE 4.
000000 05 D2 PIC 9 VALUE 5.
000000 05 FILLER PIC 9 VALUE 6.
000000 03 E PIC 9 VALUE 8.
000000 01 Y.
000000 03 B PIC X.
000000 03 C.
000000 05 C1 PIC 99 VALUE 10.
000000 05 C2 PIC 99 VALUE 10.
000000 03 D REDEFINES C.
000000 05 D1 PIC 99.
000000 05 D2 PIC 99.
000000 03 F.
000000 05 E PIC 99 VALUE 10.
000000
000000 PROCEDURE DIVISION.
000000 :
000000 ADD CORR X TO Y. *> ADD CORR
000000
000000 *> 上記の ADD CORRは下記のADDと同等である。
000000 *> ADD C1 OF C OF X TO C1 OF C OF Y.
000000 *> ADD C2 OF C OF X TO C2 OF C OF Y.
000000
000000 *> 以下のADDは行われない
000000 *> ADD B OF X TO B OF Y. (Bは英数字項目のため)
000000 *> ADD FILLER OF C OF X TO FILLER OF C OF Y. (FILLER項目は対象外であるため)
000000 *> ADD D1 OF D OF X TO D1 OF D OF Y. (D OF YはREDEFINES項目であるため)
000000 *> ADD D2 OF D OF X TO D2 OF D OF Y. (D OF YはREDEFINES項目であるため)
000000 *> ADD E OF X TO E OF F OF Y. (修飾語の系列が違うため) 6.5.4 ALTER文
一般形式
ALTER { 手続き名-1 TO [ PROCEED TO ] 手続き名-2 } …
※ SIT COBOLは、ALTER文は未サポートである。
6.5.5 CALL文
一般形式
書き方1
CALL { 一意名-1 | 定数-1 } [ USING
{ [ BY REFERENCE ] { 一意名-2 } … |
BY CONTENT { 一意名-2 | 定数-2 } … |
BY VALUE { 一意名-3 | 定数-3 } … } … ]
[ RETURNING 一意名-4 ]
[ ON OVERFLOW 無条件文-1 ]
[ END-CALL ]
書き方2
CALL { 一意名-1 | 定数-1 } [ USING
{ [ BY REFERENCE ] { 一意名-2 } … |
BY CONTENT { 一意名-2 | 定数-2 } … |
BY VALUE { 一意名-3 | 定数-3 } … } … ]
[ RETURNING 一意名-4 ]
[ ON EXCEPTION 無条件文-1 ]
[ NOT ON EXCEPTION 無条件文-2 ]
[ END-CALL ]
機能
実行単位中の他のプログラムに制御を移す。
- 一意名-1は、英数字項目でなければならない。
- 一意名-3は、数字項目でなければならない。
- 定数-1は、文字定数でなければならない。
- 定数-2は、文字定数または日本語定数でなければならない。
- 定数-3は、数字定数でなければならない。
- CALL文は、実行単位中の他のプログラムを呼び出す。CALL文を書いたプログラムを、「呼ぶプログラム」という。CALL文の実行によって呼び出されるプログラムを、「呼ばれるプログラム」という。呼ばれるプログラムの名前は、一意名-1または定数-1で指定する(*1)。呼ばれるプログラムにパラメタを渡す場合、USING指定を書く。呼ばれるプログラムが実行可能かどうかを検出する場合、ON OVERFLOW指定、ON EXCEPTION指定またはNOT ON EXCEPTION指定を書く。
- CALL文を実行したとき、CALL文で指定したプログラムが実行可能であるならば、制御は呼ばれるプログラムに移る。(*4)
- CALL文の実行による制御の移行は、ON OVERFLOW指定、ON EXCEPTION指定およびNOT ON EXCEPTION指定の有無によって異なる。CALL文の実行による制御の移行を、下表に示す。
| ON EXCEPTION指定またはON OVERFLOW指定の有無 | NOT ON EXCEPTION指定の有無 | CALL文の動作 | |
| 呼ばれるプログラムが実行不可能の場合 | 呼ばれるプログラムが実行可能の場合 | ||
| あり | あり |
[1]無条件文-1に制御が移る。 [2]無条件文-1の実行後、CALL文の終わりに制御が移る。*1 |
[1]呼ばれるプログラムに制御が移る。 [2]呼ばれるプログラムから戻った後無条件文-2に制御が移る。 [3]無条件文-2の実行後、CALL文の終わりに制御が移る *2 |
| あり | なし |
[1]無条件文-1に制御が移る。 [2]無条件文-1の実行後、CALL文の終わりに制御が移る。*1 |
[1]呼ばれるプログラムに制御が移る。 [2]呼ばれるプログラムから戻った後CALL文の終わりに制御が移る。 |
| なし | あり | CALL文の動作は、規定されない。 |
[1]呼ばれるプログラムに制御が移る。 [2]呼ばれるプログラムから戻った後無条件文-2に制御が移る。 [3]無条件文-2の実行後、CALL文の終わりに制御が移る *2 |
| なし | なし | CALL文の動作は、規定されない。 |
[1]呼ばれるプログラムに制御が移る。 [2]呼ばれるプログラムから戻った後CALL文の終わりに制御が移る。 |
*2: 無条件文-2に制御の明示移行を起こす手続き分岐または条件文を書いた場合、その文の規則に従って制御が移る。
- CALL文に指定したプログラムの検索順序は次のとおりである。
- 呼ぶプログラムが存在するフォルダに、呼ばれるプログラムと同じ名前のファイル(.cob)があるかが検査される。そのようなプログラムが見つかった場合、そのプログラムが呼ばれる。
- 次に、call_pathパラメータ(*3)で指定したフォルダに、呼ばれるプログラムと同じ名前のファイル(.cob)があるかが検査される。そのようなプログラムが見つかった場合、そのプログラムが呼ばれる。
- 呼ばれるプログラムが初期化属性を持たない場合、そのプログラムは、以下の場合に初期状態になる。
- 実行単位で最初に呼び出されたとき。
- その呼ばれるプログラムに対するCANCEL文の実行後、最初に呼び出されたとき。
上記以外の場合、実行単位で2回目以降に呼ばれるプログラムは、そのプログラムから最後に戻ったときと同じ状態になっている。
- 呼ばれるプログラムが初期化属性を持つ場合、そのプログラムは、呼び出されるときはいつでも初期状態になる。
- 呼ばれるプログラムが初期状態のとき、そのプログラムの内部ファイル結合子に関連するファイルは、開かれた状態ではない。呼ばれるプログラムが初期状態でないとき、そのプログラムの内部ファイル結合子に関連するファイルの状態およびファイルの位置付けは、そのプログラムの実行が最後に終了したときと同じ状態になっている。プログラムの初期状態については、「プログラムの初期状態」を参照のこと。
- 呼ぶプログラムの呼ぶ処理または呼ばれるプログラムから戻る処理は、外部ファイル結合子に関連するファイルの状態または位置付けを変更しない。
- COBOLプログラムを呼び出す場合、呼ばれるプログラムの手続き部の見出しまたはENTRY文にUSING指定を書いたときだけ、CALL文にUSING指定を書くことができる。その場合、USING指定の作用対象の数は、呼ぶプログラムと呼ばれるプログラムで同じでなければならない。
- CALL文のUSING指定の作用対象には、呼ばれるプログラムに渡すパラメタを指定する。呼ばれるプログラムの手続き部の見出しのUSING指定でパラメタを受け取る。各パラメタは、USING指定に書いた順によって対応付けられる。例えば、COBOLプログラムに2つのパラメタを渡す場合、CALL文のUSING指定の1番目および2番目のパラメタが、呼ばれるプログラムの手続き部の見出しのそれぞれ1番目および2番目のデータ名と対応付けられる。
- CALL文のUSING指定に書いたパラメタの値は、CALL文が実行されたときに、呼ばれるプログラムで使用可能になる。
- BY CONTENT指定、BY REFERENCE指定およびBY VALUE指定には、2つ以上のパラメタを書くことができ、これらの指定を組み合わせることもできる。これらの指定を組み合わせた場合、1つの指定は、別のBY CONTENT指定、BY REFERENCE指定またはBY VALUE指定が現れるまでのパラメタに対して有効である。最初のパラメタの前にBY CONTENT指定、BY REFERENCE指定およびBY VALUE指定のうちのどれも書かなかった場合、BY REFERENCE指定を書いたものとみなされる。
- BY REFERENCE指定を明にまたは暗に指定した場合、呼ばれるプログラムのパラメタと呼ぶプログラムのパラメタは同じ記憶領域を占有するものとみなされる。パラメタの文字位置の個数は、呼ぶプログラムと呼ばれるプログラムで同じでなければならない。
- BY CONTENT指定を書いた場合、呼ぶプログラムで指定したパラメタの値は、呼ばれるプログラムの手続き部の見出しに書いたデータ項目で参照することができる。しかし、呼ばれるプログラムでこのデータ項目を変更しても、その値は、呼ぶプログラムのパラメタに反映されない。パラメタの用途および文字位置の個数は、呼ぶプログラムと呼ばれるプログラムで同じでなければならない。
- BY CONTENT指定に定数-2を指定した場合、呼ばれるプログラムの対応するデータ項目と定数-2の属性および文字位置の個数は、互いに同じでなければならない。
- BY VALUE指定を書いた場合、パラメタの値が、直接呼ばれるプログラムに渡される。呼ばれるプログラムは、任意の数字項目で、その値を受け取ることができる(*2)。呼ばれるプログラムで、BY VALUE指定によって渡された値を変更しても、呼ぶプログラムのデータ項目の値は変更されない。
- 呼ばれるプログラムでは、呼ぶプログラムを直接または間接に呼ぶCALL文を実行することはできない。
- 宣言部の中でCALL文を実行する場合、そのCALL文は、制御が渡されていて実行が完了していない呼ばれるプログラムを直接または間接に呼ぶものであってはいけない。
- END-CALL指定は、CALL文の範囲を区切る。
- 呼ばれるプログラムの手続き部の先頭に制御を移すためには、定数-1または一意名-1に、呼ばれるプログラムのプログラム名を指定する。
- CALL文の実行の始めに、一意名-1、一意名-2および一意名-4が評価される。
- RETURNING指定が書かれた場合、一意名-1または定数-1で識別されるプログラムの結果が一意名-4に格納される。
- RETURNING指定が書かれた場合、呼び出されるプログラムの手続き部の見出しにRETURNING指定が書かれていなければならない。
- RETURNING指定が書かれなかった場合、呼び出されるプログラムの手続き部の見出しにRETURNING指定が書かれていてはならない。
- 呼び出されるプログラムでRETURNING指定の項目に値を設定しない場合、CALL文のRETURNING指定に書かれた項目の値は不定となる。
- RETURNING指定のパラメタの用途および文字位置の個数は、呼ぶプログラムと呼ばれるプログラムで同じでなければならない。
(*1)
SITCOBOLでは、一意名-1または定数-1には、呼ぶプログラムのファイル名を拡張子を除いて書く。例えば、“SUB001.cob”というプログラムを呼び出す場合には、’CALL
“SUB001” USING …’と記述する。
(*2) 例えば CALL文において「USING BY
VALUE
123.45」と指定した値は、呼ばれるプログラム側では「S9(5)V9(3)」でも「9(5)V9(2)
COMP-3」でも「COMP-1」でも数字項目であれば受け取ることができる。そのときに受け取る値は、それぞれ、+123.45,
123.45, 123 である。
(*3)
call_pathについては、「コマンドでの利用方法」の章を参照されたい。なお、SITCOBOL専用エディタにて操作する場合は、[ファイル]-[環境設定]のCALL1、CALL2、CALL3欄がcall_pathに相当する。
(*4)
呼ばれるプログラムに制御が移ったときに、カレントディレクトリは、その呼ばれるプログラムが存在するディレクトリに移る。また、その呼ばれたプログラムから戻ってきたときに、カレントディレクトリはCALL文が実行される前の状態に戻る。
書き方例1
・別プログラムの呼出し方
000000 01 C-NAME PIC X(20).
000000 :
000000 CALL "ABC". *> "ABC.cob" が呼び出される。
000000*
000000 MOVE "ABC" TO C-NAME.
000000 CALL C-NAME. *> 同じく "ABC.cob"が呼び出される。書き方例2
(サンプルプログラム名:CALL文-パラメータの受け渡し方.cob)
・パラメタの渡し方、受け取り方
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. CALL-TEST.
000020 DATA DIVISION.
000030 WORKING-STORAGE SECTION.
000040 01 P1 PIC X(20) VALUE "HOKKAIDO".
000050 01 P2 PIC X(10) VALUE "KANAGAWA".
000060 01 P3 PIC 9(5) VALUE 12345.
000070 PROCEDURE DIVISION.
000080
000090 CALL "CALL_SUB1" USING
000100 BY REFERENCE P1
000110 BY CONTENT P2 "TOKYO"
000120 BY VALUE P3 123.45.
000130*
000140 DISPLAY "P1=" P1. *> 'OKINAWA' が表示される。
000150 DISPLAY "P2=" P2. *> 'KANAGAWA'が表示される。
000160 DISPLAY "P3=" P3. *> '12345'が表示される。
000170
000180 STOP RUN.
[サンプルプログラム:CALL_SUB1.cob]
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. CALL_SUB1.
000020 DATA DIVISION.
000030 LINKAGE SECTION. *> 受け取るパラメータは連絡節で定義する。
000040 01 Q1 PIC X(20).
000050 01 Q2 PIC X(10).
000060 01 Q2-2 PIC X(5).
000070 01 Q3 COMP-1.
000080 01 Q3-2 PIC S9(10)V9(3).
000090 PROCEDURE DIVISION USING Q1 Q2 Q2-2 Q3 Q3-2.
000100
000110 DISPLAY "Q1=" Q1. *> 'HOKKAIDO'が表示される。
000120 DISPLAY "Q2=" Q2. *> 'KANAGAWA'が表示される。
000130 DISPLAY "Q2-2=" Q2-2. *> 'TOKYO'が表示される。
000140 DISPLAY "Q3=" Q3. *> '12345'が表示される。Q3はCOMP-1で定義されているが
000150 *> 数字項目であればBY VALUE指定の値は受け取れる。
000160 DISPLAY "Q3-2=" Q3-2. *> '123.45'が表示される。Q3-2はS9(10)V9(3)で定義されているが
000170 *> 数字項目であればBY VALUE指定の値は受け取れる。
000180*
000190 MOVE "OKINAWA" TO Q1. *> Q1は親のP1と領域を共有しているので値'OKINAWA'はP1に反映される。
000200 MOVE "YAMANASHI" TO Q2.*> Q2は親のP2と領域を共有していないので値'YAMANASHI'はP2に反映されない。
000210 MOVE 98765 TO Q3. *> Q3は親のP3と領域を共有していないので値98765はP3に反映されない。
000220
000230 EXIT PROGRAM. *> EXIT PROGRAMで親プログラムに戻る書き方例3
(サンプルプログラム名:CALL文-INITIAL指定のないプログラムを呼ぶケース.cob)
・INITIAL指定のないプログラムを呼ぶケース
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. CALL-TEST2.
000020 DATA DIVISION.
000030 WORKING-STORAGE SECTION.
000040 01 A PIC 9(5).
000050 PROCEDURE DIVISION.
000060
000070 CALL "CALL_SUB2" USING A.
000080 DISPLAY "A=" A. *> 1が表示される。
000090 CALL "CALL_SUB2" USING A.
000100 DISPLAY "A=" A. *> 2が表示される。
000110 CALL "CALL_SUB2" USING A.
000120 DISPLAY "A=" A. *> 3が表示される。
000130
000140 STOP RUN.
[サンプルプログラム:CALL_SUB2.cob]
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. CALL_SUB2.
000020 DATA DIVISION.
000030 WORKING-STORAGE SECTION.
000040 01 WK-DATA PIC 9(5) VALUE 0.
000050 LINKAGE SECTION.
000060 01 Q1 PIC 9(5).
000070 PROCEDURE DIVISION USING Q1.
000080 ADD 1 TO WK-DATA. *> WK-DATAの値はCALL_SUB2が呼ばれるたびに+1される。
000090 MOVE WK-DATA TO Q1.
000100 EXIT PROGRAM.(サンプルプログラム:CALL文-INITIAL指定のあるプログラムを呼ぶケース.cob)
・INITIAL指定のあるプログラムを呼ぶケース
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. CALL-TEST3.
000020 DATA DIVISION.
000030 WORKING-STORAGE SECTION.
000040 01 A PIC 9(5).
000050 PROCEDURE DIVISION.
000060
000070 CALL "CALL_SUB3" USING A.
000080 DISPLAY "A=" A. *> 1が表示される。
000090 CALL "CALL_SUB3" USING A.
000100 DISPLAY "A=" A. *> 1が表示される。
000110 CALL "CALL_SUB3" USING A.
000120 DISPLAY "A=" A. *> 2が表示される。
000130
000140 STOP RUN.
[プログラム:CALL_SUB3.cob]
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. CALL_SUB3 IS INITIAL. *> INITIAL指定のプログラム
000020 DATA DIVISION.
000030 WORKING-STORAGE SECTION.
000040 01 WK-DATA PIC 9(5) VALUE 0. *> 呼ばれるたびに0で初期化される。
000050 LINKAGE SECTION.
000060 01 Q1 PIC 9(5).
000070 PROCEDURE DIVISION USING Q1.
000080 ADD 1 TO WK-DATA. *> WK-DATAの値を呼ばれるたびに+1するが
000090 *> 毎回初期化されるので常に1になるだけ。
000100 MOVE WK-DATA TO Q1.
000110 EXIT PROGRAM.(サンプルプログラム:CALL文-CANCELされたプログラムを呼ぶケース.cob)
・CANCEL文を実行するとINITIAL指定のないプログラムも初期化される
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. CALL-TEST4.
000020 DATA DIVISION.
000030 WORKING-STORAGE SECTION.
000040 01 A PIC 9(5).
000050 PROCEDURE DIVISION.
000060
000070 CALL "CALL_SUB2" USING A.
000080 DISPLAY "A=" A. *> 1が表示される。
000090 CALL "CALL_SUB2" USING A.
000100 DISPLAY "A=" A. *> 2が表示される。
000110
000120 CANCEL "CALL_SUB2". *> CALL_SUB2をキャンセルする。
000130
000140 CALL "CALL_SUB2" USING A. *> 再びCALL_SUB2を呼び出す。
000150 DISPLAY "A=" A. *> CALL_SUB2は初期状態となったので
000160 *> 1が表示される。
000170
000180 STOP RUN.
[プログラム:CALL_SUB2.cob]
前述のCALL_SUB2.cobプログラムに同じ書き方例4
・存在しないプログラムを呼んだ場合
000000 CALL "not-exist"
000000 ON EXCEPTION
000000 DISPLAY "NG" *> 'not-exist.cob'が存在しない場合、'NG'が表示される。
000000 STOP RUN
000000 END-CALL.6.5.6 CANCEL文
一般形式
CANCEL { 一意名-1 | 定数-1 } …
機能
次回に呼び出されたときのプログラムの状態を初期状態にする。
- 一意名-1は英数字項目でなければならない。
- 定数-1は文字定数でなければならない。
- CANCEL文は、実行単位とプログラムとの論理的な関係を取り消す。取り消すプログラムの名前は、一意名-1または定数-1に指定する。CANCEL文を実行すると、一意名-1または定数-1に指定したプログラムは、CANCEL文を書いたプログラムの実行単位と論理的な関係を持たなくなる。
- CANCEL文を実行すると、CANCEL文に指定したプログラムが取り消される。
- CANCEL文の実行が成功した後、CANCEL文に指定したプログラムをその実行単位から再度呼び出したとき、そのプログラムは初期状態となる。これらの規則は、暗黙的なCANCEL文に対しても適用される。
- CANCEL文に指定したプログラムは、すでに呼び出されていて、まだEXIT PROGRAM文が実行されていないプログラムを直接または間接に参照してはならない。例えば、プログラムAの実行中に呼び出されたプログラムの中で、CANCEL“A”を実行することはできない。
- CANCEL文の実行によって取り消されたプログラムは、再度CALL文を実行したときにだけ論理的な関係が付けられる。
- CALL文によって呼び出されたプログラムは、以下のいずれかの場合に取り消される。
- そのプログラムに対するCANCEL文を実行した場合。
- そのプログラムを含む実行単位が終了した場合。
- そのプログラムが初期化属性を持つ場合で、そのプログラムでEXIT PROGRAM文を実行した場合。
上記のb.およびc.を、「暗黙的なCANCEL文」という。
書き方例
CALL文の「書き方例3」を参照のこと。
6.5.7 COMPUTE文
一般形式
COMPUTE { 一意名-1 [ ROUNDED ] } … = 算術式-1
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-COMPUTE ]
機能
算術式-1を演算し、その結果を一意名-1に格納する。
- ROUNDED指定を書かなかった場合、算術演算の結果の小数部が、結果の一意名-1の桁数に合わせて切り捨てられる。
- ROUNDED指定を書いた場合、切捨て部分の最上位の桁の値が5以上のとき、結果の一意名-2の最下位の桁の絶対値が1増やされる。
- ON SIZE ERROR 指定は、計算結果が、一意名-1
の桁数を超えた場合に実行される文を指定する。
桁あふれが発生し、ON SIZE ERROR指定がない場合は、一意名-1には桁あふれの結果が格納される。
桁あふれが発生し、ON SIZE ERROR指定がある場合は、一意名-1 の値は変更されず、無条件文-1 が実行される。
書き方例
(サンプルプログラム名:COMPUTE文.cob)
000000 01 A PIC 99V9.
000000 01 B PIC 999V9.
000000 01 C PIC 99V9 VALUE 80.1.
000000 :
000000 COMPUTE A B ROUNDED = C + 0.05. *> 算術式の結果は80.15でありAには切り捨てられた
000000 *> 結果である80.1が、BにはROUNDED(四捨五入)の結果
000000 *> である80.2が格納される
000000
000000 COMPUTE A B ROUNDED = C + 20. *> 算術式の結果は100.1である。Aは桁あふれが発生し
000000 *> 下位の00.1格納される。Bにはそのまま100.1が格納される。
000000
000000 COMPUTE A B ROUNDED = C + 25 *> 算術式の結果は105.1でありAは桁あふれが発生しているが
000000 ON SIZE ERROR *> ON SIZE ERROR指定があるので更新はされない。
000000 *> Bにはそのまま125.1が格納される。
000000 DISPLAY "A=" A " B=" B *> 桁あふれが発生したのでON SIZE ERROR指定のDISPLAY文が
000000 : *> 実行され、"A=0.1 B=125.1"が表示される。
000000 END-COMPUTE.6.5.8 CONTINUE文
一般形式
CONTINUE
機能
CONTINUE文は、プログラムの実行に何の影響も与えない。
- CONTINUE文は、条件文または無条件文が書けるところならば、どこにでも書くことができる。
6.5.9 DISPLAY文(小入出力)
一般形式
DISPLAY { 一意名-1 | 定数-1 } … [ UPON 呼び名 ]
機能
少量のデータの表示をする。
- 呼び名-1は、CONSOLE または SYSOUT でなければならない。
- UPON指定がない場合、CONSOLEが指定されたとみなす。
- 一意名-1が英数字属性、日本語属性であれば、定義された桁数の大きさで値が表示される。数字属性であれば、定義桁数によらず、評価された最終的な数値がそのまま表示される。符号付き数字項目で値が負数の場合、マイナス記号が先頭に付く。
書き方例
000000 01 A PIC S99V99 VALUE 02.10.
000000 01 B PIC S999V9 VALUE -002.1.
000000 01 C PIC X(10) VALUE "A + B = ".
000000 :
000000 DISPLAY C A " + " B. *> "A + B = 2.1 + -2.1" が表示される。6.5.10 DISPLAY文(スクリーン操作)
データを画面に表示する。
一般形式
書き方1
DISPLAY データ名-1
書き方2
DISPLAY { データ名-2 | 定数-1 } …
AT SCREEN { MESSAGE [ TIMEOUT 整数-1 [ SECOND | SECONDS ]] | CONFIRM }
[ { LINE NUMBER { 一意名-1 | 整数-2 } | COLUMN NUMBER { 一意名-2 | 整数-3 } } ]
構文規則
- データ名-1は、画面節で定義した画面項目でなければならない。その画面項目は、以下のいずれかでなければならない。
- VALUE句を指定した基本画面項目
- PICTURE句にFROM指定またはUSING指定を書いた基本画面項目
- a.またはb.の基本画面項目を従属する集団画面項目
- データ名-2は、画面節で定義した画面項目であってはならない。
- データ名-1、データ名-2は、修飾することもできる。
(※) SIT COBOLは、DISPLAY文に、LINE NUMBER句、COLUMN NUMBER句を書くことはできない。
一般規則
- 書き方1のDISPLAY文は、以下のデータを、データ名-1の画面項目に対応する画面上の領域に表示する。
- データ名-1に定数項目を指定した場合、VALUE句に指定した値を表示する。
- データ名-1に出力項目または更新項目を指定した場合、PICTURE句のFROM指定またはUSING指定に書いたデータ項目の値を画面項目へ転記し、そのデータを表示する。データ項目から画面項目への転記は、転記の規則に従って行われる。
- データ名-1に集団画面項目を指定した場合、その画面項目に従属するすべての画面項目を表示する。
- 書き方2のDISPLAY文は、画面にメッセージを表示する。MESSAGEは、確認メッセージを出力するときに指定する。CONFIRMはYES/NOの判断メッセージを出力するときに指定する。MESSAGEを指定した場合とCONFIRMを指定した場合の違いは次のとおりである。
- MESSAGEを指定し、TIMEOUTを指定しなかった場合は、画面上に、データ名-2および定数-1の値が表示され、かつ[OK]ボタンが表示される。[OK]ボタンを押す(または[ENTER]キーを押す)と、実行が終わる。
- MESSAGEを指定し、TIMEOUTを指定した場合は、画面上に、データ名-2および定数-1の値が表示され、定数-2で指定した秒数が経過すると自動的に表示が消えて実行が終わる。
- CONFIRMを指定した場合は、画面上に、データ名-2および定数-1の値が表示され、かつ[YES][NO]ボタンが表示される。[YES]または[NO]ボタンを押すと、表示が消えて実行が終わる。
- 書き方2でCONFIRM指定のDISPLAY文が実行されると、特殊レジスタCRT-STATUS(COMP-2で定義されている)の値が更新され、[YES]が押された場合は0が、[NO]が押された場合は128が設定される。
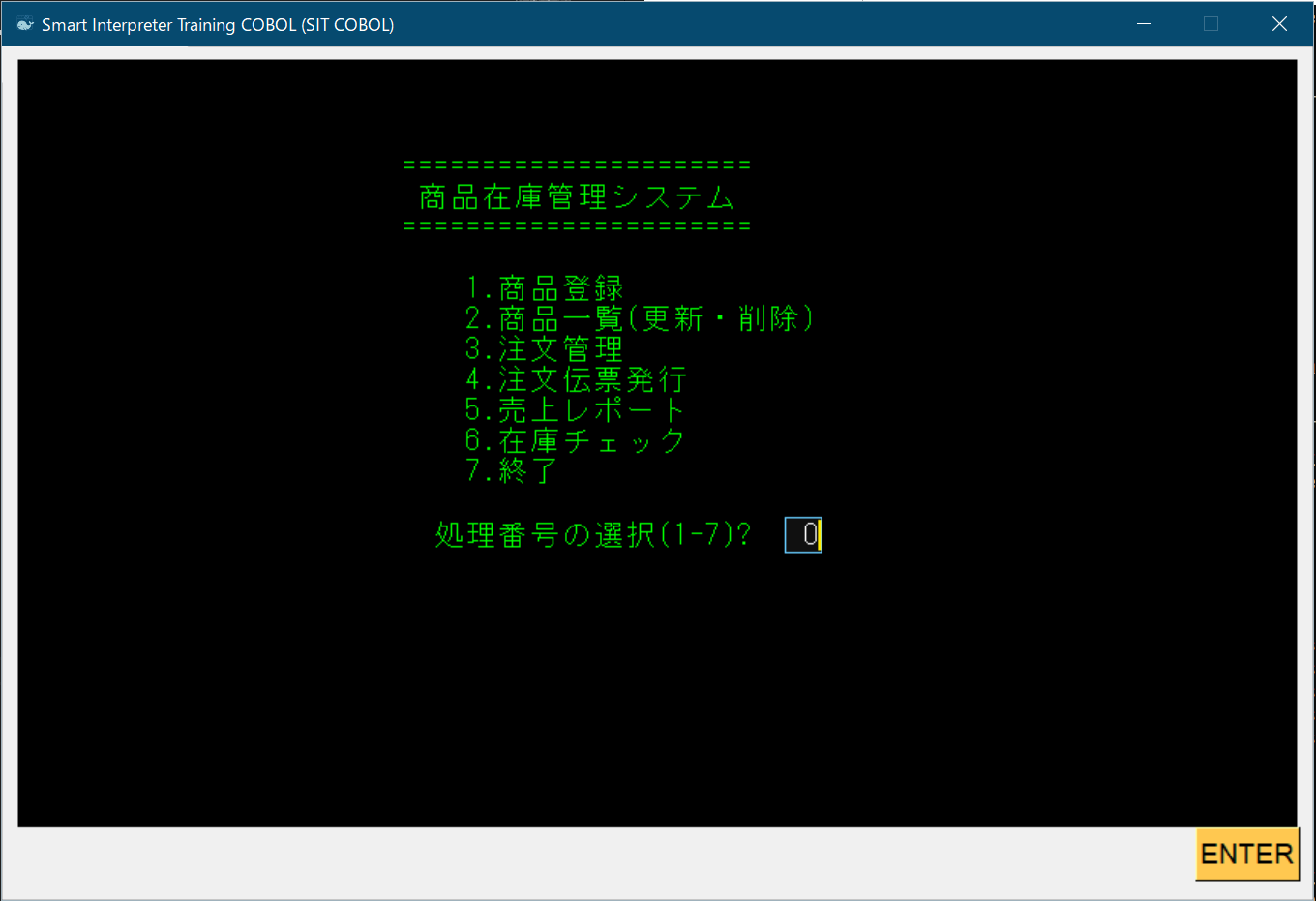
書き方1の例
001400 SCREEN SECTION.
:
001520*-----------------------------------------------------------------
001530*メインメニュ
001540*-----------------------------------------------------------------
001550 01 Sメインメニュ BLANK SCREEN.
001560 02 LINE 4 COLUMN 25 VALUE "======================".
001570 02 LINE PLUS 1 COLUMN 25 VAlUE " 商品在庫管理システム".
001580 02 LINE PLUS 1 COLUMN 25 VALUE "======================".
001590 02 LINE PLUS 2 COLUMN 25 VALUE " 1.商品登録".
001600 02 LINE PLUS 1 COLUMN 25 VALUE " 2.商品一覧(更新・削除)".
001610 02 LINE PLUS 1 COLUMN 25 VALUE " 3.注文管理".
001620 02 LINE PLUS 1 COLUMN 25 VALUE " 4.注文伝票発行".
001630 02 LINE PLUS 1 COLUMN 25 VALUE " 5.売上レポート".
001640 02 LINE PLUS 1 COLUMN 25 VALUE " 6.在庫チェック".
001650 02 LINE PLUS 1 COLUMN 25 VALUE " 7.終了".
001660 02 LINE PLUS 2 COLUMN 25 VALUE " 処理番号の選択(1-7)?".
001670 01 S処理番号? LINE 16 COLUMN 49 PIC 99 TO W-NO.
:
003080 *> メインメニューの表示
003090 DISPLAY Sメインメニュ
:003090行目のDISPLAY文によって下記のような画面が表示される。
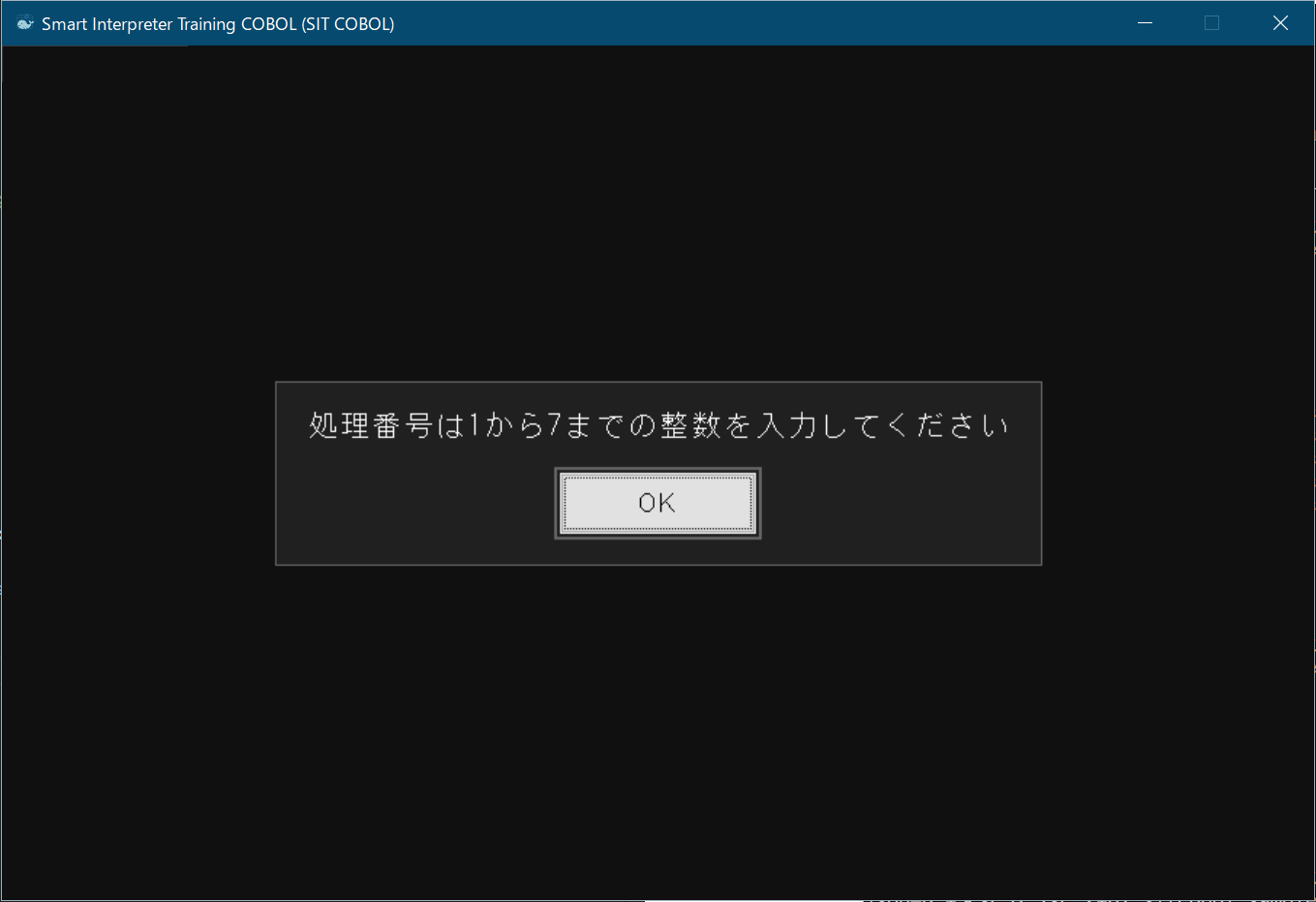
書き方2の例(1) LINE MESSAGE指定
003160 DISPLAY "処理番号は1から7までの整数を入力してください"
003170 SCREEN MESSAGE003160行目のDISPLAY文によって下記のような画面が表示されるので、確認が済んだら[OK]ボタンを押す。
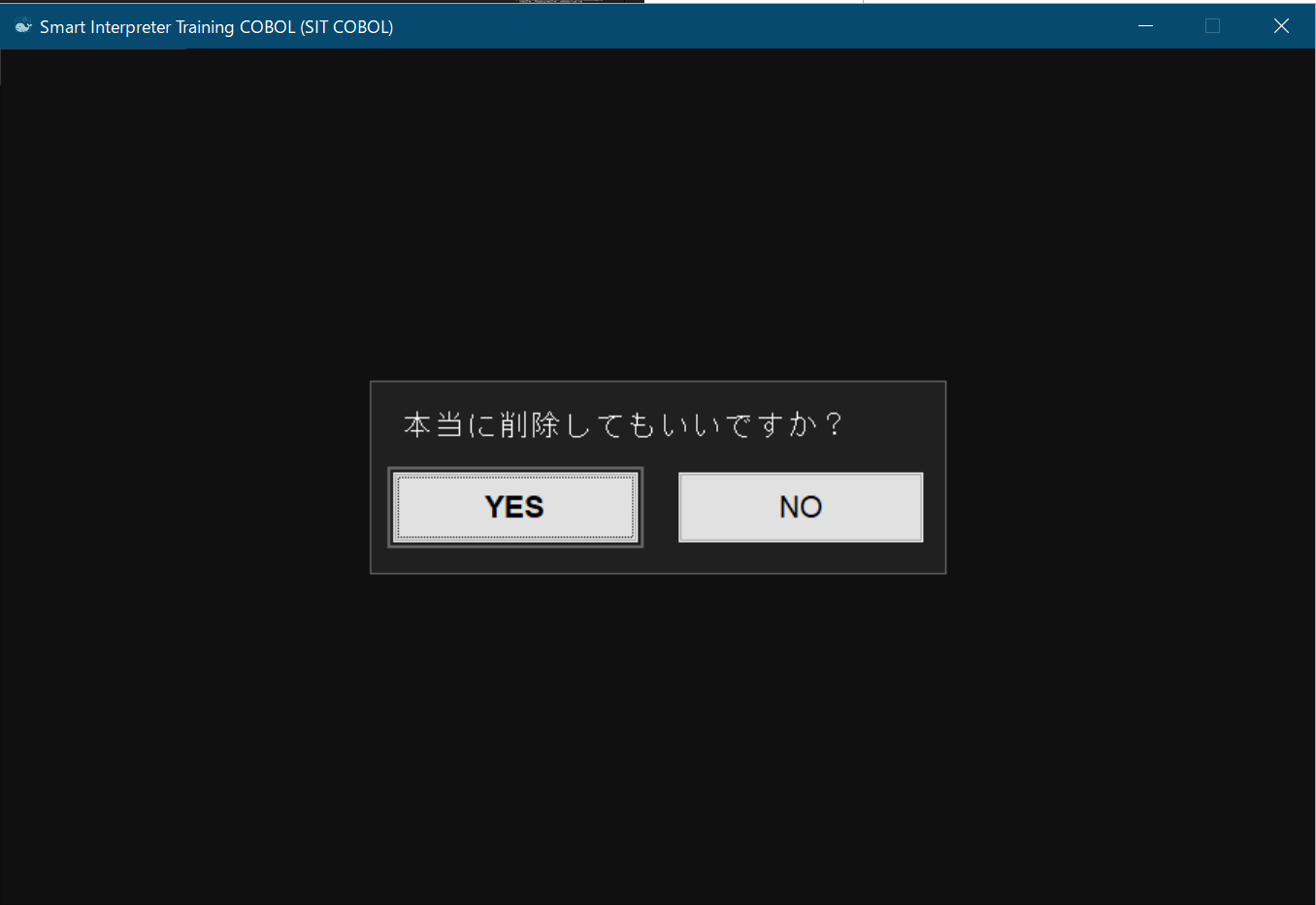
書き方2の例(2) LINE CONFIRM指定
005130 *> 削除確認で"Y"のときに商品削除
005140 DISPLAY "本当に削除してもいいですか?" SCREEN CONFIRM
005150 *> 'Y'が選択された場合のみ商品削除
005160 IF CRT-STATUS = 0
005170 PERFORM 商品削除 THRU 商品削除E
005180 DISPLAY "削除に成功しました" SCREEN MESSAGE
005190 END-IF005130行目のDISPLAY文によって下記のような画面が表示されるので、削除してもよいときは[YES]、キャンセルするときは[NO]ボタンを押す。
どちらが押されたかは、特殊レジスタCRT-STATUSで確認ができる。([YES]:
0, [NO]: 128)
6.5.11 DIVIDE文
一般形式
書き方1
DIVIDE { 一意名-1 | 定数-1 } INTO { 一意名-2 [ ROUNDED ] } …
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-DIVIDE ]
書き方2
DIVIDE { 一意名-1 | 定数-1 } INTO { 一意名-2 | 定数-2 }
GIVING { 一意名-3 [ ROUNDED ] } …
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-DIVIDE ]
書き方3
DIVIDE { 一意名-2 | 定数-2 } BY { 一意名-1 | 定数-1 }
GIVING { 一意名-3 [ ROUNDED ] } …
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-DIVIDE ]
書き方4
DIVIDE { 一意名-1 | 定数-1 } INTO { 一意名-2 | 定数-2 }
GIVING 一意名-3 [ ROUNDED ] REMAINDER 一意名-4
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-DIVIDE ]
書き方5
DIVIDE { 一意名-2 | 定数-2 } BY { 一意名-1 | 定数-1 }
GIVING 一意名-3 [ ROUNDED ] REMAINDER 一意名-4
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-DIVIDE ]
機能
書き方1
INTOの前の作用対象で一意名-2を割り、商を一意名-2に格納する。
- ROUNDED指定を書かなかった場合、算術演算の結果の小数部が、結果の一意名-2の桁数に合わせて切り捨てられる。
- ROUNDED指定を書いた場合、切捨て部分の最上位の桁の値が5以上のとき、結果の一意名-2の最下位の桁の絶対値が1増やされる。
- ON SIZE ERROR 指定は、計算結果が、一意名-2
の桁数を超えた場合に実行される文を指定する。
桁あふれが発生し、ON SIZE ERROR指定がない場合は、一意名-2には桁あふれの結果が格納される。
桁あふれが発生し、ON SIZE ERROR指定がある場合は、一意名-2 の値は変更されず、無条件文-1 が実行される。
書き方例
000000 01 A PIC S999V99 VALUE 100.
000000 01 B PIC S999V99 VALUE 100.
000000 :
000000 DIVIDE 15 INTO A *> A := A / 15 、B := B / 15 の意である。
000000 B ROUNDED. *> Aには初期値100が入っているので15で割った商の6.66が格納される。
000000 *> BはROUNDED指定なので、最終的に四捨五入した結果の、6.67が格納される。
000000 :
000000 DIVIDE 0.001 INTO A *> A := 6.66 / 0.001 の計算結果は 6660 となりAの整数桁数3を
000000 ON SIZE ERROR *> 超えるので桁あふれが発生し、ON SIZE ERROR指定の文が実行される。
000000 *> Aの内容は変わらない
000000 MOVE ...
000000 END-DIVIDE.書き方2
INTOの前の作用対象でINTOの後の作用対象を割り、商を一意名-3に格納する。
- ROUNDED指定、ON SIZE ERROR指定については、書き方1を参照のこと。
書き方例
(サンプルプログラム名:DIVIDE文-書き方2.cob)
000000 01 A PIC S9(5) VALUE 100.
000000 01 B PIC S9(5) VALUE 100.
000000 :
000000 DIVIDE 5 INTO A GIVING B. *> B := A / 5 の意である。Aには100が入っているので5で
000000 *> 割ってBには20が格納される。書き方3
BYの前の作用対象をBYの後の作用対象で割り、商を一意名-3に格納する。
- ROUNDED指定、ON SIZE ERROR指定については、書き方1を参照のこと。
書き方例
(サンプルプログラム名:DIVIDE文-書き方3.cob)
000000 01 A PIC S9(5) VALUE 100.
000000 01 B PIC S9(5) VALUE 100.
000000 :
000000 DIVIDE A BY 5 GIVING B. *> B := A / 5 の意である。Aには100が入っているので5で
000000 *> 割ってBには20が格納される。書き方4
INTOの前の作用対象でINTOの後の作用対象を割り、商を一意名-3に格納し、剰余を一意名-4に格納する。
- ROUNDED指定、ON SIZE ERROR指定については、書き方1を参照のこと。
- 剰余は、以下の式に従って求められる。
剰余 = 被除数 - 商 × 除数
被除数は、一意名-2または定数-2の値である。除数は、一意名-1または定数-1の値である。剰余を計算するために使う商として、以下の値が使われる。
- ROUNDED指定を書いた場合、商を四捨五入する前の切り捨てられた値が使われる。
- この「剰余を計算するために使う商」の桁数、小数点位置および符号の有無は、一意名-3と同じである。
- 上記以外の場合、一意名-3の値が使われる。
- ON SIZE ERROR指定を書いた場合、実行結果は以下のようになる。
- 商に桁あふれが起こった場合、一意名-3および一意名-4の内容は変更されない。
- 剰余に桁あふれが起こった場合、一意名-4の内容は変更されない。商と剰余のどちらで桁あふれが起こったかは、利用者が調べる必要がある。
書き方例
(サンプルプログラム名:DIVIDE文-書き方4.cob)
000000 01 A PIC S9(5) VALUE 100.
000000 01 B PIC S9(5).
000000 01 C PIC S9(5).
000000 :
000000 DIVIDE 15 INTO A GIVING B REMAINDER C.
000000 *> B := A / 15 であり、Aには100が入っているので15で割ってBには6が格納される。
000000 *> Cには、被除数(100) - 商(6) * 除数(15) にて計算された 10が格納される。
000000
000000 DIVIDE 15 INTO -100 GIVING B REMAINDER C.
000000 *> B := -100 / 15 であり、-100 を 15で割ってBには-6が格納される。
000000 *> Cには、被除数(-100) - 商(-6) * 除数(15) にて計算された -10が格納される。書き方5
BYの前の作用対象をBYの後の作用対象で割り、商を一意名-3に格納し、剰余を一意名-4に格納する。
- ROUNDED指定、ON SIZE ERROR指定については、書き方1を参照のこと。
- 剰余の求め方等は、書き方4に同じである。
(サンプルプログラム名:DIVIDE文-書き方5.cob)
6.5.12 ENTRY文
一般形式
ENTRY 定数-1 USING { データ名-1 } …
※ SIT COBOLは、ENTRY文は未サポートである。
6.5.13 EVALUATE文
一般形式
EVALUATE { 一意名-1 | 定数-1 | 式-1 | TRUE | FALSE }
[ ALSO { 一意名-2 | 定数-2 | 式-2 | TRUE | FALSE } ] …
{{ WHEN { ANY | 条件-1 | TRUE | FALSE | [ NOT ] {{ 一意名-3 | 定数-3 | 算術式-1 }
[ { THRU | THROUGH } { 一意名-4 | 定数-4 | 算術式-2 } ]}}
[ ALSO { ANY | 条件-2 | TRUE | FALSE | [ NOT ] {{ 一意名-5 | 定数-5 | 算術式-3 }
[ { THRU | THROUGH } { 一意名-6 | 定数-6 | 算術式-4 } ]}} ] … } …
無条件文-1 } …
[ WHEN OTHER 無条件文-2 ]
[ END-EVALUATE ]
機能
複数の条件を評価し、評価結果に対応する文を実行する。
書き方例1
例えば「数字」が1-3だったら”3以下である”、4-5だったら”3より大きい”と表示するプログラムは次のように書くことができる
000000 EVALUATE 数字
000000 WHEN 1
000000 WHEN 2
000000 WHEN 3
000000 DISPLAY "3以下である"
000000 WHEN 4
000000 WHEN 5
000000 DISPLAY "3より大きい"
000000 END-EVALUATE.もちろん、下記のように略記を使って書いてもよい
000000 EVALUATE 数字
000000 WHEN 1 OR 2 OR 3
000000 DISPLAY "3以下である"
000000 WHEN 4 OR 5
000000 DISPLAY "3より大きい"
000000 END-EVALUATE.書き方例2
- ある通販サイトの配送料は、次の表のように、顧客種別、購入金額によって定めている。EVALUATE文を使って配送料を求めるプログラムを書いてみる。
| 項番 | 顧客種別 | 購入金額 | 配送料 | |
| 1 | ゴールド会員 | 3000円以上 | 0円 | |
| 2 | ゴールド会員 | 3000円未満 | 600円 | |
| 3 | 一般会員 | 5000円以上 | 300円 | |
| 4 | 一般会員 | 5000円未満 | 900円 |
Java / C で switch-case文を使うケースに準じた書き方
000000* switch (customerType) {
000000* case "ゴールド会員":
000000* if (totalPrice > 3000)
000000* deliveryFee = 0;
000000* else
000000* deliveryFee = 600;
000000* break;
000000* default: //一般会員
000000* if (totalPrice > 5000)
000000* deliveryFee = 300;
000000* else
000000* deliveryFee = 900;
000000* };
000000*
000000* 上記に対応するEVALUATE文
000000*
000000 EVALUATE 顧客種別
000000 WHEN "ゴールド会員"
000000 IF 購入金額 > 3000
000000 MOVE 0 TO 配送料
000000 ELSE
000000 MOVE 600 TO 配送料
000000 END-IF
000000 WHEN OTHER *> "一般会員"
000000 IF 購入金額 > 5000
000000 MOVE 300 TO 配送料
000000 ELSE
000000 MOVE 900 TO 配送料
000000 END-IF
000000 END-EVALUATE.次のように記述することもできる。
000000 EVALUATE TRUE
000000 WHEN 会員種別 = "ゴールド会員" AND 購入金額 >= 3000
000000 MOVE 0 TO 配送料
000000 WHEN 会員種別 = "ゴールド会員" AND 購入金額 < 3000
000000 MOVE 600 TO 配送料
000000 WHEN 会員種別 = "一般会員" AND 購入金額 >= 5000
000000 MOVE 300 TO 配送料
000000 WHEN 会員種別 = "一般会員" AND 購入金額 < 5000
000000 MOVE 900 TO 配送料
000000 END-EVALUATE.ALSOやTHRUを使って、次のように表形式のまま書くこともできる。
(サンプルプログラム名:EVALUATE文.cob)
000000 EVALUATE 会員種別 ALSO 購入金額
000000 WHEN "ゴールド会員" ALSO 0 THRU 3000
000000 MOVE 600 TO 配送料
000000 WHEN "ゴールド会員" ALSO ANY
000000 MOVE 0 TO 配送料
000000 WHEN "一般会員" ALSO 0 THRU 5000
000000 MOVE 900 TO 配送料
000000 WHEN "一般会員" ALSO ANY
000000 MOVE 300 TO 配送料
000000 END-EVALUATE.6.5.14 EXIT文
一般形式
書き方1
EXIT
書き方2
EXIT PERFORM [ CYCLE ]
書き方3
EXIT PROGRAM
機能
書き方1
一連の手続きの共通の出口を指定する。
- EXIT文を含む段落には、EXIT文だけを書く。EXIT文は、1つのEXIT文だけで1つの完結文になっていなければならない。
- EXIT文は、手続き名を付けたいときにだけ書く。EXIT文は、プログラムの実行に対して何の影響も与えない。EXIT文を含む段落の名前は、PERFORM文のTHROUGH指定などに書くことができる。
書き方2
うちPERFORM文の出口を指定する。
- EXIT PERFORM文は、うちPERFORM文の中にだけ書くことができる。
- EXIT PERFORM文は、それが含まれる最も内側のうちPERFORM文と対応付けられる。
- CYCLE指定なしのEXIT PERFORM文を実行すると、対応するうちPERFORM文の終わりに制御が移る。
- CYCLE指定付きのEXIT PERFORM文は、終了条件付きのPERFORM文(書き方2、書き方3、書き方4、または書き方5のPERFORM文)の中にだけ書くことができる。CYCLE指定付きのEXIT PERFORM文を実行すると、対応するうちPERFORM文の検査機構に制御が移る。検査機構とは、以下処理のことである。
- 書き方2のPERFORM文で、TIMESの前に指定した繰り返し回数を検査する処理。
- 書き方3および書き方4のPERFORM文で、UNTILの後に指定した条件を検査する処理。
書き方例
000000 PERFORM 1000 TIMES
000000 READ 入力ファイル AT END
000000 EXIT PERFORM *> PERFORMを抜ける
000000 END-READ
000000 IF 入力レコード = SPACE
000000 EXIT PERFORM CYCLE *> PERFORMの先頭に戻り1000回繰り返したかの検査に入る
000000 END-IF
000000 :
000000 END-PERFORM.書き方3
呼ばれるプログラムの論理的な終わりを指定する。
- 完結文中の一連の無条件文の並びにEXIT PROGRAM文を書く場合、EXIT PROGRAM文はその並びの最後でなければならない。
- EXIT PROGRAM文は、呼び出されたプログラムの論理的な終わりを指定する。EXIT PROGRAM文を実行すると、EXIT PROGRAM文を書いたプログラムを呼び出した地点の直後に制御が戻る。CALL文の実行によってプログラムを呼び出した場合、EXIT PROGRAM文を実行すると、CALL文の直後に制御が戻る。(*1)
- EXIT PROGRAM文を実行した後の、呼び出したプログラムの状態は、呼び出したプログラムと呼び出されたプログラムで共有しているデータ項目およびファイルの内容を除いて、CALL文を実行したときの状態と同じである。
- EXIT PROGRAM文を実行した後の、呼び出されたプログラム(EXIT PROGRAM文を実行したプログラム)の状態は、以下のとおりである。
- そのプログラムが初期化属性を持たない場合、PERFORM文の範囲が決定されていることを除いて、呼び出される前の状態と同じである。
- そのプログラムが初期化属性を持つ場合、そのプログラムに対してCANCEL文を実行した結果と同じである。
- 一番最初の親プログラムにおいて、実行されるEXIT PROGRAM文は、とくに何もせず、制御は次の行に移る。
(*1) CALL文の直後に制御が戻ると同時に、カレントディレクトリも、CALL文の実行前の状態に戻る。
書き方例
CALL文の書き方例を参照のこと。
6.5.15 GENARATE文
一般形式
GENERATE { データ名-1 | 報告書名-1 }
※ SIT COBOLでは、GENERATE文は未サポートである。
機能
報告書記述に従って報告書を作成する。
6.5.16 GO TO文
一般形式
書き方1
GO TO 手続き名-1
書き方2
GO TO { 手続き名-1 } … DEPENDING ON 一意名-1
※ SIT COBOLでは、DEPENDING指定のGO TO文は未サポートである。
機能
書き方1
制御を手続き名-1に移す
書き方2
一意名-1の値が1の場合は1番目の手続き名-1、2の場合は2番目の手続き名-1というように、制御を移す。
- 手続き名-1がn個指定されているとき、一意名-1の値が整数1、2、…、n以外の場合、何もしないで次の文に制御を移す。
6.5.17 IF文
一般形式
IF 条件-1 THEN
{ {文-1} … | NEXT SENTENCE }
{ ELSE {文-2} … [ END-IF ] | ELSE NEXT SENTENCE | END-IF }
機能
- 条件-1を評価し、真の場合はTHEN指定の処理、偽の場合はELSE指定の処理を行う。
- IF文の終わりは、以下のいずれかの方法で指定する。
- 同じ水準にあるEND-IF指定。
- 分離符の終止符。
- IF文が入れ子になっている場合、外側のIF文に対応するELSE指定。
- NEXT SENTENCE指定は、制御がIF文の次の実行完結文に移ることを指定する。
(サンプルプログラム名:IF文-条件式.cob)
書き方例1: END-IFで終了
000000* 通常の書き方(IFとEND-IFが呼応)
000000 IF A = B ... [1]
000000 MOVE 1 TO FLG
000000 IF C = D ... [2]
000000 :
000000 END-IF ... [2]の終了
000000 ADD 1 TO FLG
000000 ELSE
000000 :
000000 END-IF. ... [1]の終了書き方例2: ピリオドで終了
000000* ピリオドで終了する書き方
000000 IF A = B
000000 MOVE 1 TO FLG
000000 IF C = D
000000 ADD 1 TO FLG. *> 最後のピリオドで、すべてのIF文が終わる。書き方例3: NEXT SENTENCE
NEXT SENTENCEは、次の完結文への移行、すなわち、ピリオドへの GO TO文と理解すればよい。
000000* NEXT SENTENCE
000000 IF A = B
000000 MOVE 1 TO FLG
000000 IF C = D
000000 NEXT SENTENCE *> IF文を抜けて次の完結文[1]に制御を移す
000000 ELSE
000000 :
000000 END-IF
000000 ADD 1 TO FLG
000000 ELSE
000000 :
000000 END-IF.
000000 MOVE C TO D. ... [1]6.5.18 INITIALIZE文
一般形式
INITIALIZE { 一意名-1 } …
機能
一意名-1のデータ項目を初期化する。
- 一意名-1に集団項目を指定した場合、その集団項目に従属する基本項目のうち、以下の項目は初期化の対象ではない。
- 指標データ項目
- FILLER項目
- REDEFINES句を指定した項目
- REDEFINES句を指定した項目に従属する項目
- 初期化は、対象の基本項目が英数字項目の場合はSPACEが、日本語項目の場合は、日本語の空白(SPACE)が、数字項目の場合はZEROがMOVE文により転記された結果と同等である。
(サンプルプログラム名:INITIALIZE文.cob)
6.5.19 INITIATE文
一般形式
INITIATE { 報告書名-1 } …
※ SIT COBOLは、INITIATE文は未サポートである。
機能
報告書の処理を開始する。
6.5.20 INSPECT文
一般形式
書き方1
INSPECT { 一意名-1 | 定数-6 } TALLYING { 一意名-2 FOR
{ CHARACTERS
[{ BEFORE | AFTER } INITIAL { 一意名-4 | 定数-2 }] … |
{ ALL | LEADING } {{ 一意名-3 | 定数-1 }
[{ BEFORE | AFTER } INITIAL { 一意名-4 | 定数-2 }] … } …
} …
} …
書き方2
INSPECT 一意名-1 REPLACING
{ CHARACTERS BY { 一意名-5 | 定数-3 }
[{ BEFORE | AFTER } INITIAL { 一意名-4 | 定数-2 }] … |
{ ALL | LEADING | FIRST } {{ 一意名-3 | 定数-1 } BY { 一意名-5 | 定数-2 }
[{ BEFORE | AFTER } INITIAL { 一意名-4 | 定数-2 }] … } …
} …
書き方3
INSPECT 一意名-1 TALLYING { 一意名-2 FOR
{ CHARACTERS
[{ BEFORE | AFTER } INITIAL { 一意名-4 | 定数-2 }] … |
{ ALL | LEADING } {{ 一意名-3 | 定数-1 }
[{ BEFORE | AFTER } INITIAL { 一意名-4 | 定数-2 }] … } …
} …
} …
REPLACING
{ CHARACTERS BY { 一意名-5 | 定数-3 }
[{ BEFORE | AFTER } INITIAL { 一意名-4 | 定数-2 }] … |
{ ALL | LEADING | FIRST } {{ 一意名-3 | 定数-1 } BY { 一意名-5 | 定数-2 }
[{ BEFORE | AFTER } INITIAL { 一意名-4 | 定数-2 }] … } …
} …
書き方4
INSPECT 一意名-1 CONVERTING { 一意名-6 | 定数-4 } TO { 一意名-7 | 定数-5 }
[{ BEFORE | AFTER } INITIAL { 一意名-4 | 定数-2 }] …
機能
書き方1
文字列の出現回数のカウント
- FOR指定で指定した文字列(検査文字列)が一意名-1または定数-6に含まれるかどうかを検査し、検査文字列の出現回数を数える。一意名-1または定数-6の文字列検査の範囲は、BEFORE指定またはAFTER指定で指定する。検査文字列の出現回数の数え方は、CHARACTERS指定、ALL指定またはLEADING指定で指定する。検査文字列は、一意名-3または定数-1で指定する。CHARACTERS指定の場合は、一意名-1または定数-6の文字列検査の範囲にある文字の個数を数える。
- FOR指定に2つ以上の検査文字列を指定した場合、それらの文字列は、指定した順に検査される。
- 一意名-1または定数-6の中の文字列は左から順に1回だけ検査される。
- 1つのALL指定またはLEADING指定の中に2つ以上の検査文字列を書いた場合、ALLまたはLEADINGが各検査文字列に適用される。
- INSPECT文の実行前に、一意名-2に初期値を設定しなければならない。
- 文字列検査の範囲、検査文字列の比較の手順、出現回数の考え方と文字列の置き換え方については後述の書き方1~書き方4に共通する規則を参照のこと。
(サンプルプログラム名:INSPECT文-書き方1.cob)
(サンプルプログラム名:日本語INSPECT文-書き方1.cob)
書き方例1
“>>>”と”<<<“に囲まれた文字列の数を求める。
000000 MOVE 0 TO T1.
000000 INSPECT "XYZ>>>ABCDEFG<<<*ABC" TALLYING T1 FOR CHARACTERS
000000 AFTER ">>>" BEFORE "<<<".
000000 DISPLAY "T1=" T1. *> T1=7 が表示される書き方例2
“AB”の出現回数を求める。
000000 MOVE 0 TO T2.
000000 INSPECT "ABCABCDEFDEF" TALLYING T2 FOR ALL "AB".
000000 DISPLAY "T2=" T2. *> T2=2 が表示される書き方例3
先頭から連続した”DE”の出現回数を求める。
000000 MOVE 0 TO T3.
000000 INSPECT "DEDEFDEDEF" TALLYING T3 FOR LEADING "DE".
000000 DISPLAY "T3=" T3. *> T3=2 が表示される書き方例4
上記の組み合わせ
000000 MOVE 0 TO T0 T1 T2 T3 T4.
000000 INSPECT "EFABDBCGABCFGG" TALLYING
000000 T0 FOR ALL "AB", ALL "D"
000000 T1 FOR ALL "BC"
000000 T2 FOR LEADING "EF"
000000 T3 FOR LEADING "B"
000000 T4 FOR CHARACTERS.
000000
000000 DISPLAY "T0=" T0. *> T0=3 が表示される
000000 DISPLAY "T1=" T1. *> T1=1 が表示される
000000 DISPLAY "T2=" T2. *> T2=1 が表示される
000000 DISPLAY "T3=" T3. *> T3=0 が表示される
000000 DISPLAY "T4=" T4. *> T4=5 が表示される書き方2
文字列の置き換え
- REPLACING指定で指定した文字列(検査文字列)が一意名-1に含まれるかどうかを検査し、検査文字列と一致した文字列を一意名-5または定数-3で置き換える。一意名-1の文字列検査の範囲は、BEFORE指定またはAFTER指定で指定する。文字列の置換え方は、CHARACTERS指定、ALL指定、LEADING指定またはFIRST指定で指定する。検査文字列は、一意名-3または定数-1で指定する。CHARACTERS指定の場合は、一意名-1の文字列検査の範囲にあるすべての文字を置き換える。
- REPLACING指定に2つ以上の検査文字列を書いた場合、それらの文字列は、指定した順に検査される。
- 一意名-1の文字列は左から順に1回だけ検査される。
- 1つのALL指定、LEADING指定またはFIRST指定の中に2つ以上の検査文字列を書いた場合、ALL、LEADINGまたはFIRSTが各検査文字列に適用される。
- 文字列検査の範囲、検査文字列の比較の手順、出現回数の考え方と文字列の置き換え方については後述の書き方1~書き方4に共通する規則を参照のこと。
(サンプルプログラム名:INSPECT文-書き方2.cob)
(サンプルプログラム名:日本語INSPECT文-書き方2.cob)
書き方例1
“BA”から”BC”の間にある”AB”を”XY”にする。
000000 MOVE "ABABABABC" TO 文字列.
000000 INSPECT 文字列 REPLACING
000000 ALL "AB" BY "XY" AFTER "BA" BEFORE "BC".
000000 DISPLAY "文字列=" 文字列. *> 文字列=ABABXYABC が表示される書き方例2
先頭から連続した”DE”を”XYZ”に置き換える。
000000 MOVE "DEDEFDEDEF" TO 文字列.
000000 INSPECT 文字列 REPLACING LEADING "DE" BY "XY".
000000 DISPLAY "文字列=" 文字列. *> 文字列=XYXYFDEDEF が表示される 書き方例3
最初に現れた”A”を”X”に置き換える。
000000 MOVE "THIS IS AN APPLE." TO 文字列.
000000 INSPECT 文字列 REPLACING FIRST "A" BY "X".
000000 DISPLAY "文字列=" 文字列. *> 文字列=THIS IS XN APPLE. が表示される 書き方例4
上記の組み合わせ
000000 MOVE "EFABDBCGABCFGG" to 文字列.
000000 INSPECT 文字列 REPLACING
000000 ALL "AB" BY "XY", "D" BY "X"
000000 ALL "BC" BY "VW"
000000 LEADING "EF" BY "TU"
000000 LEADING "B" BY "S"
000000 FIRST "G" BY "R"
000000 FIRST "G" BY "P"
000000 CHARACTERS BY "Z".
000000 DISPLAY "文字列=" 文字列. *> 文字列=TUXYXVWRXYZZPZ が表示される 書き方3
文字列の出現回数のカウントおよび文字列の置き換え。
- 最初にTALLYING指定だけのINSPECT文(書き方1)を書き、次にREPLACING指定だけのINSPECT文(書き方2)を書いたものと同じである。
- 文字列検査の範囲、検査文字列の比較の手順、出現回数の考え方と文字列の置き換え方については後述の書き方1~書き方4に共通する規則を参照のこと。
書き方4
置き換える文字列をまとめて指定
- REPLACINGの後にALL指定だけを2つ以上書いた書き方2のINSPECT文と同じである。
- 文字列検査の範囲、検査文字列の比較の手順、出現回数の考え方と文字列の置き換え方については後述の書き方1~書き方4に共通する規則を参照のこと。
(サンプルプログラム名:INSPECT文-書き方4.cob)
(サンプルプログラム名:日本語INSPECT文-書き方4.cob)
書き方例
“A”, “D”, “F”の文字を小文字に置き換える。
000000 MOVE "ABCDEFGHIJ" TO 文字列.
000000 INSPECT 文字列 CONVERTING "ADF" TO "adf".
000000 DISPLAY "文字列=" 文字列. *> 文字列=aBCdEfGHIJ が表示される文字列検査の範囲
- BEFORE指定とAFTER指定の両方を省略した場合、一意名-1または定数-6のすべての文字列が、文字列検査の範囲となる。
- BEFORE指定を書いた場合、一意名-1または定数-6の文字列のうち、最左端文字位置から始まり、一意名 -4または定数-2と最初に一致する文字列の直前までの文字列が、文字列検査の範囲になる。文字列検査の範囲の最右端文字の決定は、検査文字列との比較が行われる前に行われる。一意名-1または定数-6の文字列中に一意名-4または定数-2と一致する文字が出現しなかった場合、BEFORE指定を書かなかったものとみなされる。
- AFTER指定を書いた場合、一意名-1または定数-6の文字列のうち、一意名-4または定数-2と最初に一致する文字の直後の文字列から始まり、最右端文字までが、文字列検査の範囲になる。文字列検査の範囲の最左端文字の決定は、検査文字列との比較が行われる前に行われる。一意名-1または定数-6の文字列中に一意名-4または定数-2と一致する文字が出現しなかった場合、検査文字列との比較は行われない。
検査文字列の比較の手順
- 検査文字列の比較は、以下の手順で行われる。以下で、最初の「現在の最左端位置」は、一意名-1または定数-6の文字列検査の範囲の最左端の文字位置である。
- 「現在の最左端位置」から始まる文字列が、検査文字列と同じ文字数だけ、検査文字列と比較される。
- a.の比較で文字列が一致した場合、後述の「出現回数の数え方と文字列の置き換え方」の規則に従って、出現回数の加算と文字列の置換えが行われれる。そして、「現在の最左端文字位置」が、比較された文字列の最右端文字のすぐ右側の文字位置に移る。
- a.の比較で文字列が一致しなかった場合、検査文字列を2つ以上指定したときは、それらを指定した順に、「現在の最左端位置」から始まる文字列が検査文字列と比較される。この比較は、文字列が一致するかまたは検査文字列がなくなるまで繰り返される。文字列が一致した場合は、b.と同じ処理が行われる。検査文字列がなくなった場合は、“現在の最左端文字位置”が、比較された文字列の最右端文字のすぐ右側の文字位置に移る。
- 「現在の最左端位置」が一意名-1または定数-6の文字列検査の範囲を超えるまで、a.~c.の処理が繰り返される。
- CHARACTERS指定の場合、検査文字列として暗黙の1文字が仮定され、検査文字列の比較では、すべての文字が検査文字列と常に一致するものとみなされる。
出現回数の数え方と文字列の置き換え方
- ALL指定の場合、文字列検査の範囲にある、検査文字列と一致するすべての文字列が、出現回数の加算と文字列の置換えの対象になる。
- LEADING指定の場合、文字列検査の範囲の最左端位置から始まる文字列が検査文字列と一致した場合だけ、出現回数の加算と文字列の置換えが行われる。文字列検査の範囲の最左端位置から始まり、検査文字列と異なる文字列が現れるまでの文字列が、出現回数の加算と文字列の置換えの対象になる。
- FIRST指定の場合、文字列検査の範囲にある、最初に検査文字列と一致した文字列だけが、出現回数の加算と文字列の置換えの対象になる。
- CHARACTERS指定の場合、文字列検査の範囲にあるすべての文字列が、出現回数の加算と文字列の置換えの対象になる。
6.5.21 MOVE文
一般形式
書き方1
MOVE { 一意名-1 | 定数-1 } TO { 一意名-2} …
書き方2
MOVE { CORRESPONDING | CORR } 一意名-1 TO 一意名-2
機能
書き方1
- TOの前の作用対象を、TOの後の各作用対象に転記する。作用対象を「送出し側作用対象」、TOの後の各作用対象を「受取り側作用対象」という。
- 一意名-1に部分参照子または添字を付けた場合、または一意名-1に関数一意名を指定した場合、部分参照子、添字および関数一意名は、送出し側作用対象を先頭の受取り側作用対象に転記する直前に1回だけ評価される。
- 一意名-2に部分参照子または添字を付けた場合、部分参照子および添字はそれぞれの受取り側作用対象への転記を行う直前に評価される。
- 一意名-1のデータ項目の長さは、送出し側作用対象を受取り側作用対象に転記する直前に1回だけ評価される。
- 一意名-2のデータ項目の長さは、それぞれの受取り側作用対象への転記を行う直前に評価される。
- 定数には表意定数SPACE, ZERO, QUOTE, HIGH-VALUE, LOW-VALUEを書くことができる。ただし、一意名-2が日本語項目のときは、SPACEのみしか書くことしかできない。(*1)
- 一意名-1または一意名-2に可変反復データ項目を指定した場合、可変反復データ項目の長さの評価はDEPENDING ON指定のデータ項目の値によって影響される。可変反復データ項目の長さの評価については、“OCCURS句”を参照のこと。
- 送出し側作用対象と受取り側作用対象の組合せ、およびMOVE文の動作については、“転記の規則”を参照のこと。
(*1) SIT COBOLは、ZEROも書くことができる。このとき、SPACE, ZEROは暗黙のALLが指定され、それぞれ日本語の空白、ゼロと解釈される。
書き方2
一意名-1に従属するデータ項目と一意名-2に従属するデータ項目のうち、名前の修飾語の系列が同じものどうしを転記する。一意名-1に従属するデータ項目を送出し側作用対象、一意名-2に従属するデータ項目を受取り側作用対象として転記する。この結果は、対応する一意名ごとに、別々のMOVE文を書いた結果と同じである。
書き方2の例
(サンプルプログラム名:MOVE_CORR文.cob)
000040 01 X.
000050 03 B PIC X value "A".
000060 03 C.
000070 05 C1 PIC 9 value 1.
000080 05 C2 PIC 9 value 2.
000090 05 filler pic 9 value 3.
000100 03 D.
000110 05 D1 PIC 9 value 4.
000120 05 D2 PIC 9 value 5.
000130 03 E PIC 9 value 8.
000140 03 F.
000150 05 F1 PIC 9 VALUE 6.
000160 05 F2 PIC 9 VALUE 7.
000170 01 Y.
000180 03 B PIC X.
000190 03 C.
000200 05 C1 PIC 9.
000210 05 C2 PIC 9.
000220 03 D REDEFINES C.
000230 05 D1 PIC 9.
000240 05 D2 PIC 9.
000250 03 F PIC 9(2).
000260 03 E PIC 9.
:
000300 MOVE CORR X TO Y.
000000 *> このMOVE CORRで下記の転記がされる
000000 *> MOVE B OF X TO B OF Y.
000000 *> MOVE C1 OF C OF X TO C1 OF C OF Y.
000000 *> MOVE C2 OF C OF X TO C2 OF C OF Y.
000000 *> MOVE E OF X TO E OF Y.
000000 *> MOVE F OF X TO F OF Y. ... どちらか一方が集団項目の場合はOK
000000 *> 下記は受取項目が再定義項目なので実行されない。
000000 *> MOVE D1 OF D OF X TO D1 OF D OF Y.
000000 *> MOVE D2 OF D OF X TO D2 OF D OF Y.
000330 stop run.6.5.22 MULTIPLY文
一般形式
書き方1
MULTIPLY { 一意名-1 | 定数-1 } BY { 一意名-1 [ ROUNDED ]} …
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-MULTIPLY ]
書き方2
MULTIPLY { 一意名-1 | 定数-1 } BY { 一意名-2 | 定数-2 }
GIVING { 一意名-3 [ ROUNDED ]} …
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-MULTIPLY ]
機能
書き方1
BYの前の作用対象に一意名-2を掛け、一意名-2に格納する。一意名-2の並びを書いた順に、この乗算を行う。
- ROUNDED指定を書かなかった場合、算術演算の結果の小数部が、結果の一意名-1の桁数に合わせて切り捨てられる。
- ROUNDED指定を書いた場合、切捨て部分の最上位の桁の値が5以上のとき、結果の一意名-2の最下位の桁の絶対値が1増やされる。
- ON SIZE ERROR 指定は、計算結果が、一意名-1
の桁数を超えた場合に実行される文を指定する。桁あふれが発生し、ON SIZE
ERROR指定がない場合は、一意名-1には桁あふれの結果が格納される。
桁あふれが発生し、ON SIZE ERROR指定がある場合は、一意名-1 の値は変更されず、無条件文-1 が実行される。
(サンプルプログラム名:MULTIPLY文.cob)
書き方2
BYの前の作用対象にBYの後の作用対象を掛け、一意名-3に格納する。一意名-3の並びを書いた順に、この乗算の結果を格納する。
- ROUNDED指定、ON SIZE ERROR指定については、書き方1を参照のこと。
(サンプルプログラム名:MULTIPLY_GIVING文.cob)
6.5.23 PERFORM文
一般形式
書き方1
そとPERFORM
PERFORM 手続き名-1 [ { THRU | THROUGH } 手続き名-2 ]
うちPERFORM
PERFORM
無条件文-1
END-PERFORM
書き方2
そとPERFORM
PERFORM 手続き名-1 [ { THRU | THROUGH } 手続き名-2 ]
{ 一意名-1 | 整数-1 } TIMES
うちPERFORM
PERFORM { 一意名-1 | 整数-1 } TIMES
無条件文-1
END-PERFORM
書き方3
そとPERFORM
PERFORM 手続き名-1 [ { THRU | THROUGH } 手続き名-2 ]
[ WITH TEST { BEFORE | AFTER }] UNTIL 条件-1
うちPERFORM
PERFORM [ WITH TEST { BEFORE | AFTER }] UNTIL 条件-1
無条件文-1
END-PERFORM
書き方4
そとPERFORM
PERFORM 手続き名-1 [ { THRU | THROUGH } 手続き名-2 ]
[ WITH TEST { BEFORE | AFTER }]
VARYING { 一意名-2 | 指標名-1 } FROM { 一意名-3 | 指標名-2 | 定数-1 }
BY { 一意名-4 | 定数-2 } UNTIL 条件-1
[ AFTER { 一意名-5 | 指標名-3 } FROM { 一意名-6 | 指標名-4 | 定数-3 }
BY { 一意名-7 | 定数-4 } UNTIL 条件-1 ] …
※ SIT COBOLは AFTER指定は未サポートである。(サポート予定あり)
うちPERFORM
PERFORM
[ WITH TEST { BEFORE | AFTER }]
VARYING { 一意名-2 | 指標名-1 } FROM { 一意名-3 | 指標名-2 | 定数-1 }
BY { 一意名-4 | 定数-2 } UNTIL 条件-1
[ AFTER { 一意名-5 | 指標名-3 } FROM { 一意名-6 | 指標名-4 | 定数-3 }
BY { 一意名-7 | 定数-4 } UNTIL 条件-1 ] …
無条件文-1
END-PERFORM
※ SIT COBOLでは AFTER指定は未サポートである。(サポート予定あり)
書き方5
そとPERFORM
PERFORM 手続き名-1 [ { THRU | THROUGH } 手続き名-2 ] FOREVER
うちPERFORM
PERFORM FOREVER
無条件文-1
END-PERFORM
機能
書き方1
文の組を1回だけ実行する
- THROUGHとTHRUは同義語である
- 文の組を一回だけ実行し、その後、PERFORM文の終わりに制御が戻る。
書き方2
文の組の実行を、特定の回数だけ繰り返す
- THROUGHとTHRUは同義語である
- 一意名-1は、整数項目でなければならない
- 整数-1または一意名-1の初期値で指定した回数だけ、文の組を繰り返し実行する。その後、PERFORM文の終わりに制御が移る。
- PERFORM文を実行する前の一意名-1の値がゼロまたは負の場合、文の組を実行しないでPERFORM文の終わりに制御が移る。
- 文の組の実行中に一意名-1の値を変更しても、文の組の実行回数は変わらない。
書き方3
文の組の実行を、条件を満足するまで繰り返す
- THROUGHとTHRUは同義語である
- TEST BEFORE指定もTEST AFTER指定も書かない場合は、TEST BEFORE指定を書いたものとみなされる。
- 条件-1を満足するまで、文の組を繰り返し実行し、その後、PERFORM文の終わりに制御が移る。
- 文の組を実行する前に条件-1を検査する場合、TEST BEFORE指定を書くか、またはTEST定を省略する。文の組を実行した後に条件-1を検査する場合、TEST AFTER指定を書く。
- 条件-1の中の作用対象に添字または部分参照子を付けた場合、それらは、条件-1が検査されるごとに毎回評価される。
書き方4
文の組の実行を条件を満足するまで繰り返すと同時に、繰り返し回数に応じてデータ項目または指標名の値を変化させる
- THROUGHとTHRUは同義語である
- TEST BEFORE指定もTEST AFTER指定も書かない場合は、TEST BEFORE指定を書いたものとみなされる。
- 特定の条件を満足するまで文の組を繰り返し実行し、繰り返しに応じてデータ項目の値を変化させる。その後、PERFORM文の終わりに制御が移る。
- そとPERFORM文の場合、繰返しに応じて変化させるデータ項目は、VARYING指定とAFTER指定に1つ以上指定することができる。うちPERFORM文の場合、繰返しに応じて変化させるデータ項目は、VARYING指定に1つだけ指定することができる。
- 繰返しの終了条件はUNTILの後に書く。文の組を実行する前に、終了条件を検査する場合、TEST BEFORE指定を書くか、またはTEST指定を省略する。文の組を実行した後に、終了条件を検査する場合、TEST AFTER指定を書く。
- 一意名-4および一意名-7の値は、ゼロであってはならない。
- VARYING指定に指標名-1を書いた場合、FROM指定の作用対象の値は、指標名-1を持つ表の出現番号に対応する値でなければならない。また、BY指定の作用対象の値は、指標名-1を持つ表の出現番号に対応する値の増分値でなければならない。同様に、AFTER指定に指標名-3を書いた場合、FROM指定の作用対象の値は、指標名-3を持つ表の出現番号に対応する値でなければならない。また、BY指定の作用対象の値は、指標名-3を持つ表の出現番号に対応する値の増分値でなければならない。
- 条件-1を満足するまでに、指標名-1に、指標名-1を持つ表の範囲外の値を設定することはできない。同様に、条件-2を満足するまでに、指標名-3に、指標名-3を持つ表の範囲外の値を設定することはできない。ただし、PERFORM文の実行が終わったときの指標名-1の値が、1つの増分値または減分値だけ、指標名-1を持つ表の範囲外の値になることがある。
- 一意名またはUNTIL指定の条件の作用対象に添字または部分参照子を付けた場合、それらは以下の時点に評価される。
- 一意名-2および一意名-5の添字は、これらの一意名に初期値を設定するときおよび増分値を加算するとき、毎回評価される。
- 一意名-3および一意名-6の添字は、これらの一意名に初期値を設定するとき評価される。
- 一意名-4および一意名-7の添字は、一意名-2または一意名-5に増分値を加算するとき評価される。
- 条件-1および条件-2の中の一意名に付けた添字および部分参照子は、条件-1または条件-2が検査されるとき、毎回評価される。
- TEST BEFORE指定を明にまたは暗に指定し、AFTER指定を省略した場合、下図で示すように処理が行われる。(下図を省略)
- TEST BEFORE指定を明にまたは暗に指定し、AFTER指定を書いた場合、下図で示すように処理が行われる。(下図を省略)
- TEST AFTER指定を書き、AFTER指定を省略した場合、下図で示すように処理が行われる。(下図を省略)
- TEST AFTER指定を書き、AFTER指定を1つ書いた場合、下図で示すように処理が行われる。(下図を省略)
- AFTER指定を2つ以上書いた場合、AFTER指定の検査機構は、AFTER指定を1つしか書かなかった場合と同じである。ただし、先行するAFTER指定の作用対象の値が変更されるごとに各AFTER指定の作用対象の処理が一巡する。
書き方5
文の組を繰り返し実行する。この繰り返しは、制御の明示移行を示す分岐文またはEXIT PERFORM文を実行したときに終了する。
(サンプルプログラム名:外PERFORM文-段落.cob)
(サンプルプログラム名:外PERFORM文-節.cob)
(サンプルプログラム名:内PERFORM文.cob)
(サンプルプログラム名:PERFORM文-FOREVER.cob)
6.5.24 SEARCH文
一般形式
書き方1
SEARCH 一意名-1 [ VARYING { 一意名-2 | 指標名-1 }]
[ AT END 無条件文-1 ]
{ WHEN 条件-1 { 無条件文-2 | NEXT SENTENCE }} …
[ END-SEARCH ]
書き方2
SEARCH ALL 一意名-1
[ AT END 無条件文-1 ]
WHEN { データ名-1 { IS EQUAL TO | IS = } { 一意名-3 | 定数-1 | 算術式-1 } | 条件名-1 }
[ AND { データ名-1 { IS EQUAL TO | IS = } { 一意名-3 | 定数-1 | 算術式-1 } | 条件名-1 } ] …
{ 無条件文-2 | NEXT SENTENCE }
[ END-SEARCH ]
機能
書き方1
表要素を順に検索する
- 一意名-1は、INDEXED BY指定付きのOCCURS句を指定したデータ項目でなければならない。
- 一意名-2は、指標データ項目または整数項目でなければならない。一意名-1のOCCURS句のINDEXED BY指定に書いた指標名のうち、最初または唯一の指標名を使って、一意名-2を添字付けしてはならない。
- 一意名-1の表を表引き用の指標名が示す表要素から順に検索し、条件-1を満足する表要素が見つかった場合、条件-1に対応する無条件文-2の処理を実行する。
- 表要素の検索には、以下の指標名が使われる。この指標名を「表引き用の指標名」という。
- 以下の場合、一意名-1のOCCURS句のINDEXED
BY指定の中で最初に書いた指標名が使われる。
- VARYING指定を省略した場合。
- VARYING指定に一意名-1の表以外の表の指標名を書いた場合。
- VARYING指定に一意名-2を書いた場合。
- VARYING指定に一意名-1のOCCURS句のINDEXED BY指定に書いた指標名を書いた場合、その指標名が使われる。
- 表要素の検索は、以下の手順で行われる。
- 引き用の指標名の値が一意名-1の最大の出現番号に対応する値より大きい場合、表の検索は行われない。このとき、AT END指定を書いた場合は無条件文-1に制御が移り、AT END指定を省略した場合はSEARCH文の終わりに制御が移る。
- 表引き用の指標名の値が一意名-1の最大の出現番号に対応する値以下の場合、以下の処理が行われる。
- 表引き用の指標名の値が示す表要素が条件-1を満足するかどうかが検査される。検査は、WHEN指定の並びを書いた順に行われる。
- どの条件も満足しなかった場合、表引き用の指標名の値が増やされる。そして、a.の処理が繰り返される。
- 表引き用の指標名の新しい値が表の範囲外の出現番号になった場合、i.と同じ方法でSEARCH文の処理が終了する。
- 条件の1つを満足した場合、表要素の検査が終了する。そして、無条件文-2を書いた場合は無条件文-2に制御が移り、NEXT SENTENCEを書いた場合は、次の実行完結文に制御が移る。このとき、表引き用の指標名は、条件を満足したときの出現番号に対応する値になっている。
- 表引き用の指標名、一意名-2および指標名-1の値は、以下の規則に従って増加する。
- VARYING指定を省略した場合、またはVARYING指定に一意名-1のOCCURS句のINDEXED BY指定に書いた指標名を書いた場合、表引き用の指標名だけが増加する。
- VARYING指定の指標名-1に一意名-1の表以外の表の指標名を書いた場合、表引き用の指標名が増加するごとに、その増分値が示す出現番号に対応する値だけ、指標名 -1の値が増加する。
- VARYING指定に指標データ項目を書いた場合、表引き用の指標名が増加するごとに、その増分値だけ、指標データ項目の値が増加する。
- VARYING指定に整数項目を書いた場合、表引き用の指標名が増加するごとに、1だけ整数項目の値が増加する。
- WHEN指定を2つ書いた場合、表要素の検査は以下の流れ図に従って行われれる。
書き方2
昇順または降順に並んでいる表要素を非逐次に検索する
- 一意名-1は、INDEXED BY指定とKEY IS指定の両方を持つOCCURS句を指定したデータ項目でなければならない。一意名-1に、添字または部分参照子を付けてはいけない。
- データ名-1およびデータ名-2は、一意名-1のOCCURS句のKEY IS指定に書いたデータ名でなければならない。
- 条件名-1および条件名-2に対する条件変数は、一意名-1のOCCURS句のKEY IS指定に書いたデータ名でなければならない。条件名-1および条件名-2のデータ記述項のVALUE句に、THRU指定を書くことはできない。
- データ名-1、データ名-2、条件名-1または条件名-2に添字を付ける場合、1つの添字は、一意名-1のOCCURS句のINDEXED BY指定の中の最初の指標名でなければならない。
- 一意名-3、一意名-4、算術式-1の中の一意名、および算術式-2の中の一意名に、一意名-1のOCCURS句のKEY IS指定に書いたデータ名を指定することはできない。これらを添字付けしなければならない場合、添字は、一意名-1のOCCURS句のINDEXED BY指定の中の最初の指標名であってはならない。
- 一意名-1のOCCURS句のKEY IS指定に2つ以上のデータ名を書いた場合、WHEN指定のデータ名または条件名には、KEY IS指定の中の最初のデータ名から第n番目(最後でなくてもよい)までのすべてのデータ名、またはそれらのデータ名に関係付けたすべての条件名を書かなければならない。データ名と条件名は混在して書くこともできる。
- 書き方2のSEARCH文は、一意名-1の表の中からWHEN指定の条件を満足する表要素を非逐次に検索し、条件を満足する表要素が見つかった場合、無条件文-2を実行する。
- 表要素の検索には、一意名-1のOCCURS句のINDEXED BY指定の中で最初に書いた指標名が使われる。この指標名を「表引き用の指標名」という。表引き用の指標名以外の指標名の値は、変更されない。
- 書き方2のSEARCH文の実行結果は、以下のすべての条件を満足する場合だけ規定される。
- 一意名-1の表の中のデータが、一意名-1のOCCURS句のKEY IS指定の記述に従って、昇順または降順に並んでいる。
- データ名-1およびデータ名-2、または条件名-1および条件名-2の値が、表要素を一意に識別できる値である。
- 表要素の検索は、表引き用の指標名の値とは関係なく、以下の手順で行われる。
- WHEN指定に書いたすべての条件を満足する表要素が検索される。
- WHEN指定に書いたすべての条件を満足する表要素が見つからなかった場合、AT END指定を書いたときは無条件文-1に制御が移り、AT END指定を省略したときはSEARCH文の終わりに制御が移る。表引き用の指標名の値は規定されない。
- WHEN指定に書いたすべての条件を満足する表要素が見つかった場合、無条件文-2を書いたときは無条件文-2に制御が移り、NEXT SENTENCEを書いたときは次の実行完結文に制御が移る。表引き用の指標名には、条件を満足する表要素の出現番号に対応する値が設定される。
(サンプルプログラム名:SEARCH文.cob)
6.5.25 SET文
一般形式
書き方1
SET { 指標名-1 | 一意名-1 } … TO { 指標名-2 | 一意名-2 | 整数-1 }
書き方2
SET { 指標名-3 } … { UP BY | DOWN BY } { 一意名-3 | 整数-2 }
書き方3
SET { { 呼び名-1 } … TO … { ON | OFF} }
※ SIT COBOLは、書き方3のSET文は未サポートである。(サポート予定あり)
書き方4
SET { 条件名-1 } … TO TRUE
書き方5
SET ENVIRONMENT { 定数-1 | 一意名-4 } TO { 定数-2 | 一意名-5 }
機能
書き方1
表要素の指標を設定する
- 一意名-1および一意名-2は、指標データ項目または整数項目でなければならない。
- TOの後の作用対象が示す出現番号に対応する値を、TOの前の各作用対象に設定する。TOの後の作用対象を「送出し側作用対象」、TOの前の各作用対象を「受取り側作用対象」という。
- 指標名-1を書く場合、TOの後の作用対象の値は、指標名-1を関係付けた表の出現番号に対応しなければならない。
- 指標名-2を書く場合、指標名-2の値は、指標名-1を関係付けた表の出現番号に対応しなければならない。
- 受取り側作用対象を2つ以上書いた場合、指標の設定が繰り返される。繰返しにおいて指標名-2および一意名-2の値として、SET文を実行する前の値が使われる。一意名-1に添字を付けた場合、添字は繰返しごとに1つずつ順番に評価される。
- 書き方1のSET文における作用対象の組合せの可否を下表に示す。
| 送り出し側作業対象 | 受け取り側作業対象 | |||
| 指標名-1 | 一意名-1 | |||
| 指標データ項目 | 整数項目 | |||
| 指標名-2 | ○ (a) | ○ (b) | ○ (c) | |
| 一意名-2 | 指標データ項目 | ○ (a) | ○ (b) | — |
| 整数項目 | ○ (a) | ○ (b) | — | |
| 整数-1 | ○ (a) | — | — | |
指標の設定は、以下の規則に従って行わる。
- 指標名-1を書いた場合、指標名-2、一意名-2または整数-1の値に対応する出現番の値が、指標名-1に設定される。一意名-2に指標データ項目を指定した場合、または指標名-2に指標名-1と同じ表に関係付けた指標名を指定した場合は、出現番号の値の変換は行われない。
- 一意名-1に指標データ項目を指定した場合、指標名-2または一意名-2の内容と同じ値が、一意名-1に変換されずに設定される。
- 一意名-1に整数項目を指定した場合、指標名-2の値に対応する出現番号の値が一意名-1に、設定される。
書き方2
指標名の値を増減する
書き方3
外部スイッチの状態を設定する
書き方4
条件変数の値を設定する
書き方5
環境変数に値を設定する
- 定数-1, 一意名-4によって指定された環境変数名に、定数-2, 一意名-5の値を設定する。
- SIT COBOL プログラム内から生成または変更された環境変数は、そのプロラムによって生成されたすべてのサブシェルプロセスで使用できるが、SIT COBOL プログラムを開始したシェルまたはコンソールウィンドウには認識されない。
書き方例
000000 SET ENVIRONMENT "ABC" TO "XYZ". *> 環境変数ABCに値"XYZ"を設定する。(サンプルプログラム名:環境変数.cob)
6.5.26 STOP文
一般形式
STOP RUN
機能
実行を終了する。
- 開かれているファイルはすべて閉じられる。
- RETURN-CODEの値がプログラムの終了状態に設定される。(*1)
(*1) プログラムの終了状態は、Windows では、ERRORLEVELに相当する。
6.5.27 STRING文
一般形式
STRING {{ 一意名-1 | 定数-1} … DELIMITED BY { 一意名-2 | 定数-2 | SIZE }} …
INTO 一意名-3 [ WITH POINTER 一意名-4 ]
[ ON OVERFLOW 無条件文-1 ]
[ NOT ON OVERFLOW 無条件文-2 ]
[ END-STRING ]
機能
文字列を連結する
- STRING文は、一意名-1または定数-1のいくつかの文字列を連結して、一意名-3に転記する。 一意名-1および定数-1を「送出し側項目」という。一意名-3を「受取り側項目」という。 STRING文を実行すると、各送出し側項目の文字列全体または文字列の一部が、送出し側項目を書いた順に、 受取り側項目の最左端文字位置または一意名-4で指定した文字位置以降に転記される。 送出し側項目のすべての文字列を転記する場合、DELIMITED BY指定にSIZEを書く。また、送出し側項目の 最左端文字位置からある文字までの文字列を転記する場合、DELIMITED BY指定に一意名-2または定数-2を指定する。 一意名-2または定数-2を「区切り文字」という。受取り側項目の特定の文字位置以降に送出し側項目を転記する場合、 POINTER指定を書き、POINTER指定の一意名-4にその文字位置を設定する。一意名-4の値は、転記が行われるごとに 転記された文字列の長さだけ増やされる。受取り側項目の最左端文字位置以降に送出し側項目を転記する場合は、 POINTER指定を省略する。
- DELIMITED BY指定の記述に従って、各送出し側項目の中の以下の文字列が転記される。
- DELIMITED BY指定に一意名-2または定数-2を書いた場合、送出し側項目の最左端から、区切り文字と 同じ文字が現れるまでの文字列。なお、区切り文字自身は、転記されない。
- DELIMITED BY指定にSIZEを書いた場合、送出し側項目の文字列全体。
- 一意名-4の初期値は、STRING文を実行する前に設定しなければならない初期値は、1以上でなければならない。 「現在の転記位置」の初期値として、一意名-4の初期値が使われる。 「現在の転記位置」は転記が行われるごとに1ずつ変化し、STRING文の実行が終了したときの「現在の転記位置」が 一意名-4の値になる。
- POINTER指定を省略した場合、「現在の転記位置」の初期値は1である。
- 各送出し側項目から受取り側項目への転記は、転記の規則に従って、1文字ずつ行われる。 転記の際、空白詰めは行われない。各送出し側項目から受取り側項目への転記では、以下の処理が繰り返される。
- 「現在の転記位置」が受取り側項目の文字数を超えていない場合、送出し側項目の中の1文字が、現在の転記位置に 転記される。そして、「現在の転記位置」の値が1だけ増やされる。
- 「現在の転記位置」が受取り側項目の文字数を超えている場合、オーバフロー条件が発生し、転記が終了する。 そして、ON OVERFLOW指定の記述に従って、制御が移る。
- DELIMITED BY指定に書いた区切り文字を検出するか(DELIMITED BY指定に一意名-2または定数-2を書いた場合)、 送出し側項目のデータを全部転記するか、または受取り側項目の終わりに達するまでa.またはb.の処理が 繰り返される。
- 受取り側項目の中で、STRING文の実行によって値が変化するのは、転記が行われた部分だけである。 受取り側項目の他の部分は、STRING文を実行しても変化しない。
- 区切り文字に表意定数を指定した場合、表意定数は1文字の文字定数とみなされる。
- STRING文の実行で転記処理を行った後の制御の移行は、ON OVERFLOW指定およびNOT ONOVERFLOW指定の有無に よって異なる。
(サンプルプログラム名:STRING文.cob)
(サンプルプログラム名:日本語STRING文.cob) - ##### 書き方例1
000000 01 連結結果 PIC X(10).
000000 01 POINTER-1 COMP-1.
000000 :
000000 STRING "ABCDE" "fghij" DELIMITED BY SIZE INTO 連結結果.
000000 DISPLAY 連結結果. *> "ABCDEfghij"が表示される。書き方例2
000000 MOVE "**********" TO 連結結果.
000000 MOVE 3 TO POINTER-1.
000000 STRING "ABCDE" DELIMITED BY SIZE INTO 連結結果
000000 POINTER POINTER-1.
000000 DISPLAY 連結結果. *> "**ABCDE***"が表示される。書き方例3
000000 MOVE "**********" TO 連結結果.
000000 MOVE 3 TO POINTER-1.
000000 STRING "ABCDE" "fghij" DELIMITED BY SIZE INTO 連結結果
000000 POINTER POINTER-1
000000 ON OVERFLOW *> "fghij"が"fgh"までしか格納できずOVERFLOWが発生
000000 DISPLAY 連結結果 *> "**ABCDEfgh" が表示される。
000000 DISPLAY POINTER-1 *> 11が表示される。
000000 END-STRING.書き方例4
000000 77 ST-COBOL PIC X(5) VALUE "COBOL".
000000 77 ST-IS PIC X(2) VALUE "IS".
000000 77 ST-INTARESTING PIC X(20) VALUE "INTAERESTING.#012345".
000000 77 ST-RESULT PIC X(30) VALUE ALL "=".
000000 :
000000 MOVE 5 TO POINTER.
000000 STRING ST-COBOL SPACE ST-IS SPACE BY DELIMITED BY SIZE
000000 ST-INTERESTING DELIMITED BY "#"
000000 INTO ST-RESULT POINTER POINTER-1.
000000 DISPLAY ST-RESULT. *> "====COBOL IS INTERESTING.====="が表示される。6.5.28 SUBTRACT文
一般形式
書き方1
SUBTRACT { 定数-1 | 一意名-1 }
FROM { 一意名-2 [ ROUNDED ] } …
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-SUBTRACT ]
書き方2
SUBTRACT { 定数-1 | 一意名-1 } …
FROM { 定数-2 | 一意名-2 } GIVING { 一意名-3 [ ROUNDED ]} …
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-SUBTRACT ]
書き方3
SUBTRACT { CORRESPONDING | CORR } 一意名-1 FROM 一意名-2 [ ROUNDED ]
[ ON SIZE ERROR 無条件文-1 ]
[ NOT ON SIZE ERROR 無条件文-2 ]
[ END-SUBTRACT ]
機能
書き方1
FROMの前の各作用対象の和を一意名-2から引き、一意名-2に格納する。一意名-2の並びを書いた順に、この減算を行う。
- ROUNDED指定を書かなかった場合、算術演算の結果の小数部が、結果の一意名-2の桁数に合わせて切り捨てられる。ROUNDED指定を書いた場合、切捨て部分の最上位の桁の値が5以上のとき、結果の一意名-2の 最下位の桁の絶対値が1増やされる。
- ON SIZE ERROR 指定は、計算結果が、一意名-2 の桁数を超えた場合に実行される文を指定する。桁あふれが発生し、ON SIZE ERROR指定がない場合は、一意名-2には桁あふれの結果が格納される。桁あふれが発生し、ON SIZE ERROR指定がある場合は、一意名-2 の値は変更されず、無条件文-1 が実行される。
書き方2
FROMの前の各作用対象の和を、FORMの後の作用対象から引き、一意名-3に格納する。一意名-3の並びを書いた順に、この減算の結果を格納する。
- ROUNDED指定、およびON SIZE ERROR指定については、書き方1を参照のこと。
書き方3
一意名-1に従属するデータ項目と一意名-2に従属するデータ項目のうち、名前の修飾語の系列が同じものどうしの差を求める。一意名-1に従属するデータ項目を減数、一意名-2に従属するデータ項目を被減数として差を求め、一意名-2に従属するデータ項目に格納する。この結果は、対応する一意名ごとに、別々のSUBTRACT文を書いた結果と同じである。
- 対応付けるデータ項目は共に数字項目でなければならない。
- “CORRESPONDING d1 FROM d2”を書いた場合、d1に従属するデータ項目とd2に従属するデータ項目のうち、以下のすべての条件を満足するデータ項目どうしが対応付けられる。
- データ名が同じである。ただし、FILLER項目を除く。
- d1およびd2のそれぞれ直前までの修飾語の名前の系列が同じである。
- REDEFINES句、RENAMES句、OCCURS句またはUSAGE IS INDEX句を指定していない。また、 REDEFINES句、RENAMES句、OCCURS句またはUSAGE IS INDEX句を指定したデータ項目に従属していない。
- CORRESPONDINGとCORRは同義語である。
- ROUNDED指定、およびON SIZE ERROR指定については、書き方1を参照のこと。
(サンプルプログラム名:SUBTRACT文-書き方1.cob)
(サンプルプログラム名:SUBTRACT文-書き方2.cob)
(サンプルプログラム名:SUBTRACT文-書き方3.cob)
6.5.29 TRANSFORM文
データ項目の一連の文字を走査して置換する。
一般形式
TRANSFORM { 一意名-1 | 定数-3 } FROM { 定数-1 | 一意名-2 } TO { 定数-2 | 一意名-3 }
構文規則
- 定数-1, 一意名-2が、日本語項目のときは、定数-2, 一意名-3は日本語項目でなければならない。
- TRANSFORM 文は 1985 年の COBOL 標準で廃止され、 その機能は INSPECT 文の書き方4に含まれている。
一般規則
- 「TO」句の前に指定された定数-1 または一意名-2 は被置換文字列と呼ばれ、置き換える一意名-1 の文字を定義する。
- 「TO」句の後に指定された定数-2 または一意名-3 は置換文字列と呼ばれ、定数-1 または一意名-2 で指定された文字と置き換える一意名-1 の文字を定義する。
- 一意名-1 の内容が一文字ずつ走査される。その文字が被置換文字列に含まれている場合、置換文字列内の(相対位置に)対応する文字が一意名-1 の内容を置換する。
- 置換文字列の長さが被置換文字列の長さを超える場合、超過分は無視される。
- 被置換文字列の長さが置換文字列の長さを超える場合、長さの差を補うために置換文字列の右側に空白が埋め込まれていると見なされる
書き方例
(サンプルプログラム名:TRANSFORM文.cob)
(サンプルプログラム名:日本語TRANSFORM文.cob)
6.5.30 UNSTRING文
文字列を分解する。
一般形式
UNSTRING 一意名-1
[ DELIMITED BY [ ALL ] { 一意名-2 | 定数-1 } [ OR [ ALL ] { 一意名-3 | 定数-2 } ] … ]
INTO { 一意名-4 [ DELIMITER IN 一意名-5 ] [ COUNT IN 一意名-6 ]} …
[ WITH POINTER 一意名-7 ]
[ TALLYING IN 一意名-8 ]
[ ON OVERFLOW 無条件文-1]
[ NOT ON OVERFLOW 無条件文-2 ]
[ END-UNSTRING ]
構文規則
- 定数-1および定数-2は、文字定数、日本語定数、またはALLで始まらない表意定数でなければならない。
- 一意名-1、一意名-2、一意名-3および一意名-5は、英数字項目、日本語項目または日本語編集項目でなければならない。
- 一意名-4は、英字項目、英数字項目、日本語項目または数字項目でなければならない。数字項目の場合、用途は表示用で、PICTURE句は“P”を含まない文字列でなければならない。
- 一意名-6および一意名-8は、PICTURE句の文字列に“P”を含まない整数項目でなければならない。
- 一意名-7は、PICTURE句の文字列に“P”を含まない整数項目でなければならない。また、一意名-7は、一意名-1のデータ項目の文字数に1を加えた値を持つことができる大きさでなければならない。
- 一意名-1に部分参照子を付けてはならない。
- 一意名-1~一意名-5、定数-1または定数-2のいずれかの項類が日本語または日本語編集の場合、これらの項類は、すべて日本語または日本語編集でなければならない。
一般規則
- UNSTRING文は、一意名-1の文字列をDELIMITED
BY指定の条件に従って分解し、一意名-4に転記する。一意名-1を、「送出し側項目」という。一意名-4を、「受取り側項目」という。一意名-2、一意名-3、定数-1および定数-2を、「区切り文字」という。
DELIMITED BY指定付きのUNSTRING文は、送出し側項目の最左端文字位置または特定の文字位置以降の文字列を区切り文字で区切り、区切った順に各受取り側項目に転記する。
DELIMITED BY指定なしのUNSTRING文は、送出し側項目の最左端文字位置または特定の文字位置以降の文字列を、各受取り側項目の長さで区切り、区切った順に各受取り側項目に転記する。
送出し側項目の最左端文字位置以降の部分を転記の対象にする場合、POINTER指定を省略する。送出し側項目の特定の文字位置以降の部分を転記の対象にする場合、POINTER指定を書き、POINTER指定の一意名-7にその文字位置を設定する。一意名-7の値は、区切り文字との比較が行われるごとに増やされる。
各受取り側項目への転記において、区切り文字または区切り文字までの文字の個数を得ることができる。区切り文字を得る場合、DELIMITER IN指定を書く。区切り文字までの文字の個数を得る場合、COUNT IN指定を書く。
また、受取り側項目のうち、実際に文字列が転記された受取り側項目の個数を数えることができる。転記された受取り側項目の個数を数える場合、TALLYING IN指定を書く。 - 一意名-7の初期値は、UNSTRING文を実行する前に設定しなければならない。初期値は、1以上でなければならない。「現在の検査位置」の初期値として、一意名-7の初期値が使われる。「現在の検査位置」の値は、送出し側項目の文字が検査されるごとに、1ずつ増やされる。UNSTRING文の実行が終了したときの「現在の検査位置」の値が、一意名-7の値になる。
- POINTER指定を省略した場合、「現在の検査位置」の初期値は1である。
- DELIMITED BY指定を書いた場合、送出し側項目が以下の手順で分割され、各受取り側項目に転記される。以下で、最初の「現在の受取り側項目」は、INTO指定に書いた最初の一意名-4である。
- 「現在の検査位置」が送出し側項目の文字数を超えていない場合、「現在の検査位置」以降の送出し側項目が、区切り文字と1文字ずつ比較される。区切り文字を2つ以上書いた場合、同じ位置から始まる文字列が、区切り文字を書いた順に区切り文字と一致するまで繰り返し比較される。区切り文字が2文字以上の場合、区切り文字と同じ文字数の文字列が、区切り文字と比較される。
「現在の検査位置」が送出し側項目の文字数を超えている場合、区切り文字の検査を終了する。 - a.の比較操作で「現在の検査位置」より後に区切り文字と一致する文字が見つかった場合、「現在の検査位置」から区切り文字と一致した文字の前までの文字列が、「現在の受取り側項目」に転記される。このとき、区切り文字と一致した文字は、転記されません。DELIMITER IN指定を書いた場合、区切り文字が一意名-5に転記される。
- a.の比較操作で区切り文字と一致する文字が見つからなかった場合、送出し側項目の文字列が「現在の受取り側項目」に転記される。DELIMITER IN指定に書いた一意名-5には、空白が転記される。
- a.の比較操作で「現在の検査位置」の文字が区切り文字と一致した場合、以下の値が「現在の受取り側項目」に転記される。
- 「現在の受取り側項目」が英字項目、英数字項目または日本語項目の場合、空白が転記される。
- 「現在の受取り側項目」が数字項目の場合、ゼロが転記される。
- COUNT IN指定を書いた場合、「現在の受取り側項目」に転記された文字の個数が、一意名-6に設定される。d.の場合は、一意名-6にゼロが設定される。
- 「現在の検査位置」と「現在の受取り側項目」が以下のように変更され、送出し側項目のすべての文字がなくなるかまたは受取り側項目がなくなるまで、a.~f.の処理が繰り返される。
- 区切り文字と一致した文字のすぐ右の文字位置が「現在の検査位置」になる。
- 次の受取り側項目が「現在の受取り側項目」になる。
- DELIMITED BY指定を省略した場合、送出し側項目が以下の手順で分割され、各受取り側項目に転記される。以下で、「現在の受取り側項目」の初期値は、INTO指定の中の最初の一意名-4である。
- 「現在の検査位置」が送出し側項目の文字数を超えていない場合、「現在の検査位置」以降の送出し側項目の文字数が、「現在の受取り側項目」の文字数と比較される。「現在の受取り側項目」が数字項目の場合、その文字数として以下の値が使われる。
- SIGN句にSEPARATEを指定した場合、演算符号の文字数を除いた文字数が使われる。
- PICTURE句で小数点を指定した場合、小数点の文字数を除いた文字数が使われる。
- 「現在の検査位置」が送出し側項目の文字数を超えている場合、転記を終了する。
- 「現在の検査位置」から始まる「現在の受取り側項目」の文字数だけの文字列が、「現在の受取り側項目」に転記される。そして、「現在の検査位置」と「現在の受取り側項目」が以下のように変更され、送出し側項目のすべての文字がなくなるか、または受取り側項目がなくなるまで、a.~c.の処理が繰り返される。
- 転記された最後の文字のすぐ右の文字位置が「現在の検査位置」になる。
- 次の受取り側項目が「現在の受取り側項目」になる。
- TALLYING指定を書いた場合、受取り側項目のうち、実際に文字列が転記された受取り側項目の数が、一意名-8に加算される。一意名-8には、初期値を設定しておかなければならない。一意名-8の値は、1つの一意名-4ごとに1ずつ増加する。
- 区切り文字に表意定数を指定した場合、表意定数は1文字の文字定数とみなされる。
- 区切り文字の前にALLを書いた場合、送出し側項目の文字列のうち、区切り文字と同じ文字が現れてから区切り文字以外の文字が現れるまでの文字は、読み飛ばされる。DELIMITER IN指定を書いた場合、読み飛ばされた文字数とは関係なく、1回の繰返しの区切り文字が一意名-5に設定される。
- 区切り文字には、計算機文字集合中の任意の文字を設定することができる。
- UNSTRING文の実行で転記処理が行われた後の制御の移行は、ON OVERFLOW指定およびNOT ON OVERFLOW指定の有無によって異なる。転記処理の後の制御の移行を、下表に示する。
| ON OVERFLOW指定の有無 | NOT ON OVERFLOW句の有無 | 制御の移行 | |
| 転記処理でオーバーフロー条件が発生した場合(*3) | 転記処理でオーバーフロー条件が発生しなかった場合 | ||
| あり | あり |
[1]転記が終了し、無条件文-1に制御が移る。 [2]無条件文-1の実行後、UNSTRING文の終わりに制御が移る。(*1) |
[1]すべての転記が終了した後、無条件文-2に制御が移る。 [2]無条件文-2の実行後、UNSTRING文の終わりに制御が移る。(*2) |
| あり | なし |
[1]転記が終了し、無条件文-1に制御が移る。 無条件文-1の実行後、UNSTRING文の終わりに制御が移る(*1) |
すべての転記が終了した後、UNSTRING文の終わりに制御が移る |
| なし | あり | 転記が終了し、UNSTRING文の終わりに制御が移る。 |
[1]すべての転記が終了した後、無条件文-2に制御が移る。 無条件文-2の実行後、UNSTRING文の終わりに制御が移る。(*2) |
| なし | なし | 転記が終了し、UNSTRING文の終わりに制御が移る。 | すべての転記が終了した後、UNSTRING文の終わりに制御が移る。 |
(*1)
無条件文-1に制御の明示移行を起こす手続き分岐または条件文を書いた場合、その文の規則に従って制御が移る。
(*2)
無条件文-2に制御の明示移行を起こす手続き分岐または条件文を書いた場合、その文の規則に従って制御が移る。
(*3)
オーバーフロー条件は、以下の場合に発生する。
- 一意名-4の初期値が、1より小さいかまたは一意名-3の文字列の文字数より大きいとき。
- 「現在の転記位置」が、一意名-3の文字列の文字数より大きくなったとき。すなわち、一意名-3の最右端まで転記されたのに、送出し側項目の中に、転記されない文字が残っているとき。
- END-UNSTRING指定は、UNSTRING文の範囲を区切る。
- 以下の場合、この文の実行結果は規定されない。
- 一意名-1~一意名-3が、一意名-4~一意名-8と同じ記憶領域を占有する場合。
- 意名-4~一意名-6が、一意名-7または一意名-8と同じ記憶領域を占有する場合。
- 一意名-7が一意名-8と同じ記憶領域を占有する場合。
書き方例
(サンプルプログラム名:UNSTRING文.cob)
(サンプルプログラム名:日本語UNSTRING文.cob)
6.6 ファイル入出力文
この節では、ファイル入出力操作に関する各文について説明する。
6.6.1 CLOSE文
ファイルの処理を終了させる。
書き方
CLOSE ファイル名-1 [ ファイル名-2 ] …
構文規則
- ファイル名-1の並びに、ORGANIZATION句の指定の異なるファイルまたはACCESS MODE句の指定の異なるファイルを指定することもできる。
一般規則
- CLOSE文を実行すると、ファイル名-1の入出力状態の値が更新される。
- ファイル名-1を2つ以上書いた場合のCLOSE文の実行結果は、ファイル名-1を書いた順に、各ファイルに対して別々のCLOSE文を実行した結果と同じである。
6.6.2 DELETE文
大記憶ファイルからレコードを論理的に取り除く。
書き方
DELETE ファイル名-1 RECORD
[ INVALID KEY 無条件文-1 ]
[ NOT INVALID KEY 無条件文-2 ]
[ END-DELETE ]
構文規則
- ファイル名-1に順呼出し法のファイルを指定する場合、INVALID KEY指定またはNOT INVALID KEY指定を書くことはできない。
- ファイル名-1に乱呼出し法または動的呼出し法のファイルを指定し、ファイル名-1に関連するUSE AFTER STANDARD EXCEPTION手続きを書かない場合、INVALID KEY指定を書かなければならない。
- 索引ファイルの場合、ファイル名-1は、DUPLICATES指定付きのRECORD KEY句を指定した乱呼出し法のファイルであってはならない。
一般規則
共通する規則
- ファイル名-1のファイルは、大記憶ファイルでなければならない。
- ファイル名-1のファイルは、DELETE文を実行する前に、入出力両用モードで開いておかなければならない。
- ファイル名-1に順呼出し法のファイルを指定した場合、DELETE文を実行する前に、ファイル名-1のファイルに対するREAD文を実行しなければならない。READ文の実行が成功した場合、DELETE文を実行すると、READ文によって読み込まれたレコードがファイルから取り除かれる。
- 他のファイル結合子によってロックされているレコードを削除しようとすると、DELETE文の実行は不成功になる。そして、レコードのロックを示す値が、ファイル名-1の入出力状態に設定される。
- DELETE文の実行が成功すると、削除の対象となるレコードがファイルから論理的に取り除かれる。それ以後、そのレコードを参照することはできない。
- DELETE文を実行しても、ファイル位置指示子は変更されない。
- DELETE文を実行しても、そのレコード領域の内容、およびファイル名-1のファイル記述項のRECORD句のDEPENDING ON指定に指定したデータ項目の内容は変更されない。
- DELETE文を実行すると、ファイル名-1の入出力状態の値が更新される。
- DELETE文の実行が成功すると、存在するレコードのロックが解除される。
- DELETE文の実行中に無効キー条件が発生すると、ファイル名-1の入出力状態に無効キー条件を示す値が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- DELETE文の実行中に例外条件が発生しなかった場合、ファイル名-1の入出力状態が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- END-DELETE指定は、DELETE文の範囲を区切る。
6.6.3 OPEN文
ファイルを使用可能な状態にする。
書き方
OPEN {
{ INPUT ファイル名-1 [ WITH LOCK] } …
{ OUTPUT ファイル名-2 [ WITH LOCK] } …
{ I-O ファイル名-3 [ WITH LOCK] } …
{ EXTEND ファイル名-4 [ WITH LOCK] } …
} …
(※) SIT COBOLは、WITH
LOCK指定は未サポートである。(サポート予定)
構文規則
各ファイルに共通する規則
ファイル名-1~ファイル名-4の並びに、ORGANIZATION句の指定が異なるファイルまたはACCESS MODE句の指定が異なるファイルを指定することもできる。
相対および索引ファイルの規則
EXTEND指定を書く場合、ファイル名-4は順呼出し法のファイルでなければならない。
一般規則
各ファイルに共通する規則
以下で、“ファイル名-n”は、ファイル名-1~ファイル名-4に指定したファイルを表す。
- OPEN文の実行が成功すると、ファイル名-nのファイルはプログラムで使用可能になり、開いた状態になる。OPEN文の実行が成功すると、そのファイルは、ファイル結合子を通してファイル名と関連付けられる。
- ファイル名-nのファイルが、物理的に存在し入出力管理システムに認識された状態を「ファイルが使用可能」という。認識されていない状態を、「ファイルが使用不可能」という。それぞれの状態でOPEN文を実行したときの結果を、下表に示す。
| OPEN文の指定 | ファイルが使用可能 | ファイルが使用不可能 |
| INPUT | ファイルが開かれる。 | OPEN文は不成功になる。 |
|
INPUT (不定ファイルの場合) |
ファイルが開かれる。 | ファイルが開かれる。最初の読込みでファイル終了条件または無効キー条件になる。 |
| I-O | ファイルが開かれる。 | OPEN文は不成功になる。 |
|
I-O (不定ファイルの場合) |
ファイルが開かれる。 | OPEN文の実行で、ファイルが生成される。 |
| OUTPUT | ファイルが開かれる。ただし、そのファイルにはレコードがない状態。 | OPEN文の実行で、ファイルが生成される。 |
| EXTEND | ファイルが開かれる。 | OPEN文は不成功になる。 |
|
EXTEND (不定ファイルの場合) |
ファイルが開かれる。 | OPEN文の実行で、ファイルが生成される。 |
- OPEN文の実行が成功すると、ファイル名-nのレコード領域が使用可能になる。
- ファイルを開く前に、そのファイルに対する入出力文を実行することはできない。
- INPUT指定、OUTPUT指定、I-O指定およびEXTEND指定は、ファイルのオープンモードを指定する。ファイルを開いた後に実行できる入出力文は、オープンモードによって異なる。オープンモードと入出力文の関係については、“入出力文の動作”を参照のこと。
- OPEN文は、最初のレコードの読み書きを行わない。
- 1つの実行単位中で、1つのファイルに対するOPEN文を2回以上実行する場合、次のOPEN文を実行する前に、LOCK指定のないCLOSE文を実行しなければなりない。
- OPEN文の実行中にファイル属性不整合条件が発生すると、OPEN文の実行は不成功になり、以下の処理が順に行われる。
- ファイル名-nの入出力状態が設定される。
- ファイル名-nに関連するUSE AFTER STANDARD EXCEPTION手続きを書いた場合、その手続きが実行される。そして、その手続きの実行後、USE文の規則に従って制御が渡される。USE AFTER STANDARD EXCEPTION手続きを書かなかった場合、ファイル名-nにFILE STATUS句を指定したときは、OPEN文の最後に制御が移る。USE AFTER STANDARD EXCEPTION手続きもFILE STATUS句も書かなかったときの実行結果は、規定されない。
- OPEN文を実行すると、ファイル名-nの入出力状態の値が更新される。
- I-O指定を書く場合、ファイル名-3のファイルは、入力文と出力文の両方を実行することができるファイルでなければならない。I-O指定のOPEN文の実行が成功すると、入力文と出力文の両方の実行が可能になる。
- LOCK指定は、ファイルのロックのモードを指定する。ファイルのロックのモードは、ファイル管理記述項のLOCK MODE句とOPEN文の記述によって決まる。ファイルのロックのモードについては、“ファイルの共用と排他”を参照してください。
- LOCK指定を書いた場合、OPEN文の実行によって、ファイル名-nのファイルに対するロックが取得される。これは、ファイル名-nのLOCK MODE句でEXCLUSIVEを書いたことと同じである。
- 排他モードのOPEN文の実行が成功すると、ファイル名-nのファイル結合子に関連するファイルが、排他的にロックされる。ファイル名-nのファイルがすでに他のファイル結合子によって開かれている場合は、OPEN文の実行は不成功になる。
- 共用モードのOPEN文の実行が成功した後、ファイル名-nのファイルを1つ以上のファイル結合子によって開くことができる。ファイル名-nのファイルがすでに他のファイル結合子によって排他的に開かれている場合は、OPEN文の実行は不成功になる。
- 不定ファイルに対して、実行単位中で最初にINPUT指定のOPEN文を実行すると、ファイル位置指示子は不定ファイルが存在しないことを指示するように設定される。
- まだ生成されていない不定ファイルに対するEXTEND指定またはI-O指定のOPEN文の実行が成功すると、ファイルが生成される。ファイルの生成は、以下の順に2つの文を実行したかのように行われる。
- OPEN OUTPUT ファイル名-n
- CLOSE ファイル名-n
生成されたファイルは、レコードが存在しない状態になっている。
- ファイル名-nを2つ以上書いた場合のOPEN文の実行結果は、書いた順に、各ファイルに対して別々のOPEN文を実行した結果と同じである。
- ファイルの最小のレコードの大きさおよび最大のレコードの大きさは、利用者の指定に従って、ファイルを生成したときに決定される。その後は変更できない。
順ファイルの規則
- INPUT指定またはI-O指定のOPEN文の実行が成功すると、ファイル名-nのファイル位置指示子に1が設定される。
- EXTEND指定のOPEN文の実行が成功すると、ファイルはその最後のレコードの直後に位置付けられる。順ファイルの最後のレコードは、そのファイルで最後に書き出されたレコードである。
相対ファイルの規則
- INPUT指定またはI-O指定のOPEN文の実行が成功すると、ファイル名-nのファイル位置指子は1に設定される。
- EXTEND指定のOPEN文の実行が成功すると、ファイルはその最後のレコードの直後に位置付けられる。相対ファイルの最後のレコードは、すでに存在するレコードのうち最高の相対レコード番号を持つものである。
索引ファイルの規則
- INPUT指定またはI-O指定のOPEN文の実行が成功すると、ファイル名-nのファイル位置指示子は、そのファイルの主レコードキーが取りうる最小の値に設定される。また、主レコードキーが参照キーとして設定される。
- EXTEND指定のOPEN文の実行が成功すると、ファイルはその最後のレコードの直後に位置付けられる。索引ファイルの最後のレコードは、すでに存在するレコードのうち最大の主レコードキーの値を持つレコードである。ただし、RECORD KEY句にDUPLICATES指定を書いた場合、索引ファイルの最後のレコードは、すでに存在するレコードで最大の主レコードキーの値を持つレコードのうち、最後に生成されたレコードである。
6.6.4 READ文
ファイルからレコードを読む。
書き方1
レコードを順読みする(順・相対・索引)
READ ファイル名-1 [ NEXT ] RECORD
[ INTO 一意名-1 ]
[ WITH [ NO ] LOCK ]
[ AT END 無条件文-1 ]
[ NOT AT END 無条件文-2 ]
[ END-READ ]
書き方2
レコードを乱読みする。(相対ファイル)
READ ファイル名-1 RECORD
[ INTO 一意名-1 ]
[ WITH [ NO ] LOCK ]
[ INVALID KEY 無条件文-3 ]
[ NOT INVALID KEY 無条件文-4 ]
[ END-READ ]
書き方3
レコードを乱読みする。(索引ファイル)
READ ファイル名-1 RECORD
[ INTO 一意名-1 ]
[ WITH [ NO ] LOCK ]
[ KEY IS { データ名-1 } … ]
[ INVALID KEY 無条件文-3 ]
[ NOT INVALID KEY 無条件文-4 ]
[ END-READ ]
(※) SIT COBOLは、WITL
LOCK指定は未サポートである。(サポート予定あり)
(※) SIT
COBOLは、書き方3において、データ名-1を複数指定することはできない。(サポート予定あり)
構文規則
各ファイルに共通する規則
- 一意名-1の記憶領域とファイル名-1のレコード領域は、異なる領域でなければならない。
- ファイル名-1に関連するUSE AFTER STANDARD EXCEPTION手続きを書かない場合、AT END指定またはINVALID KEY指定を書かなければならない。ただし、SIT COBOLでは、USE STANDARD EXCEPTION手続きとAT END指定またはINVALID KEY指定の両方を省略することができる。
相対ファイルの規則
- 順呼出し法のファイルからレコードを読む場合、書き方1を使う。
- 動的呼出し法のファイルから順にレコードを読む場合、書き方1を使う。NEXT指定は書かなければならない。
- 乱呼出し法のファイルからレコードを読む場合、または動的呼出し法のファイルから乱にレコードを読む場合、書き方2を使う。
索引ファイルの規則
- 順呼出し法のファイルからレコードを読む場合、書き方1を使う。
- 動的呼出し法のファイルから順にレコードを読む場合、書き方1を使う。NEXT指定は書かなければならない。
- 乱呼出し法のファイルからレコードを読む場合、または動的呼出し法のファイルから乱にレコードを読む場合、書き方3を使う。
- データ名-1は、ファイル名-1のRECORD KEY句またはALTERNATE RECORD KEY句に指定したデータ名でなければならない。RECORD KEY句のデータ名を指定する場合、RECORD KEY句にデータ名を2つ以上指定しているならば、データ名-1の並びは、RECORD KEY句に指定したデータ名の並びと、指定順序および個数とも同じでなければならない。また、ALTERNATE RECORD KEY句のデータ名を指定する場合、ALTERNATE RECORD KEY句にデータ名を2つ以上指定しているならば、データ名-1の並びはALTERNATE RECORD KEY句に指定したデータ名の並びと、指定順序および個数とも同じでなければならない。
- データ名-1は、修飾することができる。
一般規則
書き方1,2,3に共通する規則
各ファイルに共通する規則
- ファイル名-1のファイルは、READ文を実行する前に入力モードまたは入出力両用モードで開いておかなければならない。
- READ文を実行すると、ファイルから読み込むレコードが選択され、ファイル名-1のファイル位置指示子の値が設定される。また、ファイル名-1の入出力状態の値が更新される。ファイル位置指示子の値によって次にとる動作が決定される。
- READ文の実行が不成功になった場合、ファイル名-1のレコード領域の内容は規定されない。ファイル位置指示子は、次の有効なレコードがないことを示すように設定される。
- ファイル位置指示子の値が有効なレコードがあることを示している場合、レコードは、レコード領域で使用可能になる。INTO指定を書いた場合、レコード領域から一意名-1へレコードが転送される。
- 読み込んだレコードの文字位置の個数がファイル名-1のレコード記述項で指定した最小レコードの大きさより小さい場合、ファイル名-1のレコード領域のうち、読み込んだレコードの文字位置の個数を超える部分の内容は規定されない。読み込んだレコードの文字位置の個数がファイル名-1のレコード記述項で指定した最大レコードの大きさより大きい場合、読み込んだレコードの右側が最大レコードの大きさに合わせて切り捨てられ、ファイル名-1のレコード領域に設定される。どちらの場合も、READ文は成功する。ファイル名-1の入出力状態には、レコード長矛盾を示す値が設定される。
- END-READ指定は、READ文の範囲を区切る。
INTO指定の規則
- INTO指定は、以下の場合に書くことができる。
- ファイル名-1のレコード記述項を1つだけ書いた場合。
- ファイル名-1に関連するすべてのレコード名および一意名-1が、集団項目または英数字項目の場合。
- INTO指定を書いた場合、以下の順に処理が行われる。
- INTO指定のない同じREAD文が実行される。
- a.のREAD文の実行が成功した場合、現在のレコードが、CORRESPONDING指定なしのMOVE文の規則に従って、ファイル名-1のレコード領域から一意名-1の領域へ転記される。読み込まれたレコードは、ファイル名-1のレコード領域と一意名-1のデータ項目の両方で使用可能になる。
現在のレコードの大きさは、ファイル名-1のRECORD句の規則に従って決定される。ファイル名-1のファイル記述項に書き方3以外のRECORD句を書いた場合、b.では集団項目転記が行われる。一意名-1に付けた添字は、a.の後b.の前に評価される。a.のREAD文が不成功の場合、暗黙のMOVE文は実行されない。
レコードのロックの規則
- LOCK MODE IS AUTOMATIC句を指定したファイルに対して以下のREAD文を実行すると、読み込まれたレコードがロックされる。
- WITH LOCK指定を書いたREAD文。
- WITH LOCK指定もWITH NO LOCK指定も書いていないREAD文。
- LOCK MODE IS MANUAL句を指定したファイル(相対ファイルまたは索引ファイル)に対して、WITH LOCK指定を書いたREAD文を実行すると、読み込まれたレコードがロックされる。
- 入力モードで開いたファイルに対してREAD文を実行した場合、レコードはロックされない。WITH LOCK指定を書いても書かなくても同じである。
- 明にまたは暗にロックを伴うREAD文の実行が開始されるとき、そのREAD文によって読み込まれるレコードが、他のファイル結合子によってロックされているならば、そのREAD文の実行は不成功になる。ファイル名-1の入出力状態には、レコードのロックを示す値が、設定される。このとき、ファイル位置指示子の値は変更されない。
書き方1の規則
各ファイルに共通する規則
- ファイル名-1に順ファイル、順呼出し法の相対ファイルまたは順呼出し法の索引ファイルを指定した場合、NEXT指定は省略することができる。NEXT指定はREAD文の実行には影響を与えない。
- ファイル名-1に順ファイル、順呼出し法の相対ファイルまたは順呼出し法の索引ファイルを指定したREAD文は、ファイル名-1のファイルから次のレコードを呼び出す。
- ファイル名-1に動的呼び出し法の相対ファイルまたは動的呼び出し法の索引ファイルを指定し、NEXT指定を書いたREAD文は、ファイル名-1から次のレコードを呼び出す。
- READ文を実行すると、使用可能なレコードを定めるための規則に従って、ファイル位置指示子の値が決定される。ファイル位置指示子の値によって、次にとる動作が決定される。
使用可能なレコード(順)
- READ文の実行が開始されるときのファイル位置指示子の値は、以下の規則に従って使用可能なレコードを定めるために使われる。順ファイルでのレコードの比較は、レコード番号によって行われる。
- ファイル位置指示子が次の有効なレコードが存在しないことを示している場合、READ文の実行は不成功になる。
- ファイル位置指示子が不定ファイルが存在しないことを示している場合、ファイル終了条件が発生する。
- 先に実行したOPEN文によりファイル位置指示子が設定されている場合、ファイル位置指示子より大きいかまたは等しいレコード番号を持つ、ファイル中の最初のレコードが選択される。
- 先に実行したREAD文によりファイル位置指示子が設定されている場合、ファイル位置指示子より大きいレコード番号を持つ、ファイル中の最初のレコードが選択される。
- 1.のc.またはd.の条件を満足するレコードが見つからなかった場合、ファイル終了条件が発生する。ファイル位置指示子には、次のレコードが存在しないことを示す値が設定される。
- 1.のc.またはd.の条件を満足するレコードが見つかった場合、そのレコードがファイル名 -1に関連するレコード領域で使用可能になる。そして、ファイル位置指示子が、使用可能になったレコードのレコード番号に設定される。
使用可能なレコード(相対)
- READ文の実行が開始されるときのファイル位置指示子の値は、以下の規則に従って使用可能なレコードを定めるために使われる。相対ファイルでのレコードの比較は、相対キー番号によって行われる。
- ファイル位置指示子が有効な次のレコードがないことを示しているとき、READ文の実行は不成功になる。
- ファイル位置指示子が不定ファイルが存在しないことを示している場合、ファイル終了条件が発生する。
- 先に実行されたOPEN文によりファイル位置指示子が設定されている場合、ファイル位置指示子と等しいかまたは大きい相対レコード番号を持つ最初のレコードが選択される。
- 先に実行されたSTART文によりファイル位置指示子が設定されている場合、そのファイル位置指示子と同じ相対レコード番号を持つレコードが選択される。
- 先に実行されたREAD文によりファイル位置指示子が設定されている場合、そのファイル位置指示子より大きい相対レコード番号を持つ最初のレコードが選択される。
- 1.のc.またはd.の条件を満足するレコードが見つからなかった場合、ファイル終了条件が発生する。ファイル位置指示子には、次のレコードが存在しないことを示す値が設定される。
- 1.のc.またはd.の条件を満足するレコード(「選択されたレコード」という)が見つかった場合、以下の処理が行われる。
- ファイル名-1に対してRELATIVE KEY指定を書いた場合、選択されたレコードの相対レコード番号の有効桁数と相対キー項目の大きさが比較される。
- 相対レコード番号の有効桁数が相対キー項目の大きさより大きい場合、ファイル終了条件が発生する。
- このとき、ファイル位置指示子には、相対レコード番号の有効桁数が相対キー項目の大きさを超えたことを示す値が設定される。
- 相対レコード番号の有効桁数が相対キー項目の大きさ以下の場合、選択されたレコードがファイル名-1のレコード領域で使用可能になる。このとき、ファイル位置指示子には、使用可能になったレコードの相対レコード番号が設定される。また、転記の規則に従って、使用可能になったレコードの相対レコード番号が相対キー項目に転記される。
- ファイル名-1に対してRELATIVE KEY指定を書かなかった場合、選択されたレコードが、ファイル名-1のレコード領域で使用可能になる。このとき、ファイル位置指示子には、使用可能になったレコードの相対レコード番号が設定される。
使用可能なレコード(索引)
- READ文の実行が開始されるときのファイル位置指示子の値は、以下の規則に従って、使用可能なレコードを定めるために使われる。索引ファイルでのレコードの比較は、現在の参照キーの値の大小順序によって行われる。
- ファイル位置指示子が次のレコードが存在しないことを示している場合、READ文の実行は不成功になる。
- ファイル位置指示子が不定ファイルが存在しないことを示している場合、ファイル終了条件が発生する。
- 先に実行されたOPEN文によりファイル位置指示子が設定されている場合、現在の参照キーによるファイル中の先頭レコードが選択される。
- 先に実行されたSTART文によりファイル位置指示子が設定されている場合、そのファイル位置指示子と同じキー値を持つレコードが選択される。
- 先に実行されたREAD文によりファイル位置指示子が設定されている場合、以下のいずれかの条件を満足するレコードが選択される。
- 先に実行されたREAD文により使用可能となったレコードの、論理的に直後のレコード。
- 1.のc.、d.およびe.で、条件を満足するレコードが見つからなかった場合、ファイル終了条件が発生する。ファイル位置指示子には、次のレコードが存在しないことを示す値が設定される。
- 1.のc.、d.およびe.で、条件を満足するレコードが見つかった場合、そのレコードがファイル名-1のレコード領域で使用可能になる。そして、ファイル位置指示子には、使用可能になったレコードの現在の参照キーの値が設定される。
- READ文の実行が不成功になった場合、参照キーの値は規定されない。
- 主レコードキーまたは副レコードキーを参照キーとしてREAD文を実行した場合、参照キーの値を持つレコードが2つ以上存在することがある。その場合、以下の順にレコードが読み込まれる。
- WRITE文またはREWRITE文で、参照キーの値が重複するレコードを生成した順に、レコードが読み込まれる。
- 動的呼出し法のファイルに対して、書き方3のREAD文に続いて書き方1のREAD文を実行すると、書き方1のREAD文では以下に示す参照キーが使われ、かつ以下に示す検索方向でレコードが読み込まれる。
- 参照キーが変更されるまで、書き方3のREAD文の実行によって設定された参照キーが使用される。
- REVERSED ORDER指定付きのSTART文が実行されるまで、正順で検索される。
例外条件の発生時の制御
- READ文の実行中にファイル終了条件が発生すると、READ文の実行が不成功になる。ファイル名-1の入出力状態にファイル終了条件を示す値が設定された後、“AT END指定”の規則に従って制御が移る。
- READ文の実行中にファイル終了条件以外の例外条件が発生すると、ファイル位置指示子およびファイル名-1の入出力状態が設定された後、“AT END指定”の規則に従って制御が移る。
- READ文の実行中にファイル終了条件もその他の例外条件も発生しなかった場合、以下の処理が順に行われる。
- ファイル位置指示子およびファイル名-1の入出力状態が設定される。
- 読み込んだレコードがレコード領域で使用可能になる。INTO指定を書いた場合、暗黙の転記も実行される。
- “AT END指定”の規則に従って制御が移る。
行順ファイルの規則
- 行順ファイルに対するREAD文を実行すると、レコードのデータは以下のように設定される。
- レコードの区切り文字までの長さが最大レコード長と同じ場合、レコードの区切り文字までの部分がレコード領域に設定される。
- レコードの区切り文字までの長さが最大レコード長より短い場合、レコードの区切り文字までの部分がレコード領域に設定され、レコード領域の残りの部分には空白が設定される。
- レコードの区切り文字までの長さが最大レコード長より長い場合、最大レコード長と同じ長さのデータが読み込まれ、それ以降の区切り文字までのデータは破棄される。
書き方2の規則
- READ文の実行が開始されるときのファイル位置指示子が、入力の不定ファイルが存在しないことを示している場合、無効キー条件が発生する。READ文の実行は不成功になる。
- READ文を実行する前に、ファイル名-1の相対キー項目に、読み込みたいレコードの相対レコード番号を設定しておく必要がある。READ文を実行すると、ファイル位置指示子に相対キー項目の値が設定される。そして、ファイル位置指示子の値と等しい相対レコード番号を持つレコードが見つかった場合、そのレコードがファイル名-1に関連するレコード領域で使用可能になる。ファイル位置指示子の値と等しい相対レコード番号を持つレコードが見つからなかった場合、無効キー条件が発生し、READ文の実行は不成功になる。
書き方3の規則
- READ文の実行が開始されるときのファイル位置指示子が、入力の不定ファイルが存在しないことを示している場合、無効キー条件が発生する。READ文の実行は不成功になる。
- KEY指定を書いた場合、データ名-1がREAD文の参照キーになる。
- KEY指定を省略した場合、主レコードキーがREAD文の参照キーになる。
- READ文の実行によって、ファイル位置指示子に参照キーの値が設定される。そして、ファイルから読み込むレコードを選択するために、レコードの参照キーに対応する部分がファイル位置指示子の値と比較される。この比較は、参照キーに対応する部分がファイル位置指示子の値と一致する最初のレコードが見つかるまで行われる。主レコードキーまたは副レコードキーが重複した値を持つ場合は、重複した参照キーを持つ一連のレコードの中の最初のレコードが見つかるまで、比較が行われる。
この比較の結果、条件を満足するレコードが見つかった場合、そのレコードがファイル名 -1に関連するレコード領域で使用可能になる。条件を満足するレコードが見つからなかった場合、無効キー条件が発生する。この場合、READ文の実行が不成功になる。 - READ文の実行が不成功になった場合、参照キーの値は規定されない。
書き方2・書き方3に共通する規則
- READ文の実行中に無効キー条件が発生すると、ファイル名-1の入出力状態に無効キー条件を示す値が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- READ文の実行中に無効キー条件以外の例外条件が発生すると、ファイル位置指示子およびファイル名-1の入出力状態が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- READ文の実行中に無効キー条件もその他の例外条件も発生しなかった場合、以下の処理が順に行わる。
- ファイル位置指示子およびファイル名-1の入出力状態が設定される。
- 読み込んだレコードがレコード領域で使用可能になる。INTO指定を書いた場合、暗黙の転記も実行される。
- “INVALID KEY指定”の規則に従って制御が移る。
6.6.5 REWRITE文
大記憶ファイル中のレコードを論理的に書き換える。
一般形式
書き方1
順に読んだレコードを書き換える。
REWRITE レコード名-1 [ FROM 一意名-1 ]
[ END-REWRITE ]
書き方2
指定したレコードを書き換える(相対ファイル・索引ファイル)
REWRITE レコード名-1 [ FROM 一意名-1 ]
[ INVALID KEY 無条件文-1 ]
[ NOT INVALID KEY 無条件文-2 ]
[ END-REWRITE ]
構文規則
各ファイルに共通する規則
- レコード名-1は、データ部のファイル節で定義したレコードの名前でなければならない。レコード名-1は、ファイル名で修飾することができる。
- 一意名-1にデータ項目を指定する場合、レコード名-1の領域と一意名-1の領域は同じであってはいけない。一意名-1に関数一意名を指定する場合、英数字関数でなければならない。
相対ファイルの規則
- レコード名-1に順呼出し法のファイルを指定する場合、書き方1のREWRITE文を書かなければならない。
- レコード名-1に乱呼出し法または動的呼出し法のファイルを指定する場合、書き方2のREWRITE文を書かなければならない。この場合、関連するUSE AFTER STANDARD EXCEPTION手続きを書かないときは、INVALID KEY指定を書かなければならない。
索引ファイルの規則
- レコード名-1に関連するファイルは、DUPLICATES指定付きのRECORD KEY句を指定した乱呼出し法のファイルであってはならない。
- レコード名-1に関連するファイルに関連するUSE AFTER STANDARD EXCEPTION手続きを書かない場合、INVALID KEY指定を書かなければならない。
一般規則
各ファイルに共通する規則
- レコード名-1に関連するファイルは、大記憶ファイルでなければならない
- レコード名-1に関連するファイルは、REWRITE文を実行する前に入出力両用モードで開いておかなければならない
- REWRITE文の実行が成功すると、レコード名-1のレコードはレコード領域で使用不可能になる。ただし、入出力管理段落のSAME RECORD AREA句にレコード名-1に関連するファイルを指定した場合、REWRITE文によってレコードが使用不可能になることはない。そのレコードは、そのプログラムで使用可能である。
- FROM指定を書いたREWRITE文の実行結果は、以下に示す文をこの順で実行した結果と同じである。
- MOVE 一意名-1 TO レコード名-1
- FROM指定のない同じREWRITE文
- REWRITE文の実行が完了した後、SAME RECORD AREA句にレコード名-1に関連するファイルを指定している場合を除いて、レコード名-1の領域の情報は使用不可能になる。ただし、一意名-1の領域の情報は使用可能である。
- REWRITE文を実行しても、ファイル位置指示子は変更されない。
- REWRITE文を実行すると、レコード名-1に関連するファイルの入出力状態の値が更新される。
- REWRITE文の実行によって、レコードが入出力管理システムに渡される。
- 他のファイル結合子によってロックされているレコードを書き換えようとすると、REWRITE文の実行は不成功になる。そして、レコードのロックを示す値が、レコード名-1に関連する入出力状態に設定される。
- レコード名-1に関連するファイルのLOCK MODE句にAUTOMATICを指定した場合、REWRITE文の実行が成功すると、存在するレコードのロックが解除される。
- END-REWRITE指定は、REWRITE文の範囲を区切る。
順ファイルの規則
- REWRITE文を実行する前に、レコード名-1に関連するファイルに対してREAD文を実行しなければならない。READ文の実行が成功した場合、REWRITE文を実行すると、READ文によって読み込まれたレコードが論理的に書き換えられる。
- レコード名-1のレコードの文字位置の個数と書き換えられるレコードの長さが異なる場合、REWRITE文の実行は不成功になり、レコードは書き換えられない。レコード名-1のレコード領域の内容は変更されない。このとき、以下の処理が順に行われる。
- レコード名-1に関連するファイルの入出力状態に、この状態の原因を示す値が設定される。
- レコード名-1に関連するファイルのUSE AFTER STANDARD EXCEPTION手続きを書いた場合、その手続きが実行される。そして、その手続きの実行後、USE文の規則に従って制御が渡される。USE AFTER STANDARD EXCEPTION手続きを書かなかった場合、レコード名-1に関連するファイルにFILE STATUS句を指定したときは、REWRITE文の最後に制御が移る。USE AFTER STANDARD EXCEPTION手続きもFILE STATUS句も書かなかったときの実行処理は、規定されない。
相対ファイルの規則
- 順呼出し法のファイルに対するREWRITE文(書き方1のREWRITE文)の場合、REWRITE文を実行する前に、レコード名-1に関連するファイルに対してREAD文を実行しなければならない。READ文の実行が成功した場合、REWRITE文を実行すると、READ文によって読み込まれたレコードが書き換えられる。
- 乱呼出し法または動的呼出し法のファイルに対してREWRITE文(書き方2のREWRITE文)を実行すると、相対キー項目の値と同じ相対レコード番号を持つレコードが書き換えられる。相対キー項目の値と同じ相対レコード番号を持つレコードがファイルに存在しない場合は、無効キー条件が発生する。
索引ファイルの規則
- 以下の場合、REWRITE文を実行する前に実行される最後の入出力文は、レコード名-1に関連するファイルに対するREAD文でなければならない。READ文の実行が成功した場合、REWRITE文を実行すると、READ文によって読み込まれたレコードが書き換えられる。
- 順呼出し法のファイルに対するREWRITE文
- DUPLICATES指定付きのRECORD KEY句を指定したファイルに対するREWRITE文
- 順呼出し法のファイルに対するREWRITE文の場合、書き換えるレコードを主レコードキーの値で指定する。REWRITE文を実行するとき、書き換えるレコードの主レコードキーの値は、このファイルから最後に読み込まれたレコードの主レコードキーの値と等しくなければならない。
- 各DUPLICATES指定付きのRECORD KEY句を指定したファイルに対するREWRITE文の場合、書き換えるレコードを主レコードキーで指定する。REWRITE文を実行するとき、書き換えるレコードのレコードキーの値は、このファイルから最後に読み込まれたレコードのレコードキーの値と等しくなければならない。
- 乱呼出し法または動的呼出し法のファイルの場合、書き換えるレコードを主レコードキーの値で指定する。
- レコード名-1に関連するファイルにALTERNATE RECORD KEY句を指定した場合、REWRITE文の実行は、副レコードキーの値により以下のように行われる。
- 副レコードキーの値が変わらないとき、そのキーが参照キーであっても、レコードの検索の順序は変わらない。
- 副レコードキーの値が変わるとき、その副レコードキーが参照キーであれば、レコードの検索の順序が変わることがある。重複したキー値が許されているとき、そのレコードは、設定された副レコードキーの値と同じ副レコードキーの値を持つレコードの組の中の論理的に最後の位置を占める。
- 以下の場合、無効キー条件が発生する。
- 以下の条件を満足するREWRITE文で、書き換えようとするレコードの主レコードキーの値が、同じファイルから最後に読み込まれたレコードの主レコードキーの値と等しくない場合。
- 順呼出し法のファイルに対するREWRITE文
- DUPLICATES指定付きのRECORD KEY句を指定したファイルに対するREWRITE文
- REVERSED ORDER指定付きのSTART文によりファイル位置指示子が確定したファイルに対するREWRITE文
- 動的呼出し法または乱呼出し法のファイルに対するREWRITE文で、書き換えようとするレコードの主レコードキーの値に等しいレコードが、ファイル中に存在しない場合。
- DUPLICATES指定なしのALTERNATE RECORD KEY句を指定したファイルに対するREWRITE文で、書き換えようとするレコードの副レコードキーの値と等しい副レコードキーの値を持つレコードが、ファイル中にすでに存在する場合。
相対・索引に共通する規則
- レコード名-1のレコードの文字位置の個数は、書き換えられるレコードの長さと同じである必要はない。
- レコード名-1のレコードの文字位置の個数は、レコード名-1に関連するファイルの最大レコード長より大きくてはならない。この場合、REWRITE文の実行は不成功になり、レコードは書き換えられない。レコード名-1に関連するファイルのレコード領域の内容は変更されない。レコード名-1に関連するファイルの入出力状態には、この状態の原因を示す値が設定される。
- REWRITE文の実行中に無効キー条件が発生すると、REWRITE文の実行は不成功になり、レコードは書き換えられない。レコード名-1に関連するファイルの入出力状態に無効キー条件を示す値が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- REWRITE文の実行中に無効キー条件以外の例外条件が発生すると、レコード名-1に関連するファイルの入出力状態が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- REWRITE文の実行中に無効キー条件もその他の例外条件も発生しなかった場合、以下の処理が順に行われる。
- レコード名-1に関連するファイルの入出力状態が設定される。
- READ文によって読み込まれたレコードが書き換えられる。
- “INVALID KEY指定”の規則に従って制御が移る。
6.6.6 START文
レコードを順呼出しするためにファイルを論理的に位置付ける。
書き方
START ファイル名-1
[ KEY
{ IS EQUAL TO |
IS = |
IS GREATER THAN |
IS > |
IS NOT LESS THAN |
IS NOT < |
IS GREATER THAN OR EQUAL TO |
IS >= } データ名-1
[ INVALID KEY 無条件文-1 ]
[ NOT INVALID KEY 無条件文-2 ]
[ END-START ]
[備考]
=”、“>”、“<”、“>=”および“<=”は必要語である。ここでは、他の記号との混同を避けるために下線を付けていない。
構文規則
- ファイル名-1は、順呼出し法または動的呼出し法のファイルでなければならない。
- データ名-1は、修飾することができる。
- ファイル名-1に関連するUSE AFTER STANDARD EXCEPTION手続きを書かない場合、INVALID KEY指定を書かなければならない。
- KEY指定を書く場合、データ名-1は以下のいずれかでなければならない。
- ファイル名-1に関連するファイル管理記述項のRECORD KEY句に書いたデータ項目(主レコードキー項目)またはALTERNATE RECORD KEY句に書いたデータ項目(副レコードキー項目)。
- 以下の条件をすべて満足するデータ項目である。
- ファイル名-1に関連するレコードの中に存在し、左端の文字位置が主レコードキー項目の左端の文字位置と等しい。
- 大きさが主レコードキー項目の大きさより小さいか等しい。
- 英数字項目、日本語項目または集団項目である。
- ファイル名-1に関連するALTERNATE RECORD KEY句にデータ名を書いた場合で、以下の条件をすべて満足するデータ項目。
- ファイル名-1に関連するレコードの中に存在し、左端の文字位置が副レコードキー項目の左端の文字位置と等しい。
- 大きさが副レコードキー項目の大きさより小さい、または等しい。
- 英数字項目、日本語項目または集団項目である。
一般規則
- ファイル名-1のファイルは、START文を実行する前に入力モードまたは入出力両用モードで開いておかなければらなない。
- START文を実行しても、レコード領域の内容は変更されない。また、ファイル名-1に関連するRECORD句のDEPENDING ON指定に指定したデータ項目の内容も変更されない。
- START文を実行すると、ファイル名-1の入出力状態の値が更新される。
- START文を実行する前に、ファイル位置指示子が不定ファイルが存在しないことを示している場合、無効キー条件が発生し、START文の実行は不成功になる。
- START文の実行が不成功になった場合、ファイル位置指示子には、有効な次のレコードがないことを示す値が設定される。参照キーは規定されない。
- 参照キーは、以下の規則に従って決定される。以下の規則は、この順序で適用される。
- KEY指定を省略した場合、ファイル名-1の主レコードキーが参照キーになる。
- KEY指定のデータ名-1に、RECORD KEY句に書いたデータ名以外かつALTERNATE RECORD KEY句に書いたデータ名以外のデータ名を指定した場合、以下の条件をすべて満足するレコードキーが参照キーになる。
- 最左端の文字位置がデータ名-1のデータ項目の最左端の文字位置と対応する。
- 大きさがデータ名-1のデータ項目の大きさより大きい、または等しい。
- ただ1つのデータ項目から構成されている。
- 英数字項目、日本語項目または集団項目である。
- 上記b.の条件をすべて満足するレコードキーが2つ以上存在する場合は、以下に示すレコードキーが参照キーになる。
- 主レコードキーが、b.の条件を満足する場合、主レコードキーが参照キーになる。
- 主レコードキーが、b.の条件を満足しない場合、条件を満足する副レコードキーのうち、大きさが最も小さい副レコードキーが参照キーになる。大きさが最も小さい副レコードキーが2つ以上存在する場合は、ALTERNATE RECORD KEY句で先に指定した副レコードキーが参照キーになる。
- 6.の規則に従って決定された参照キーが、START文でレコードキーの順序を定めるために使われる。START文の実行が成功した場合、START文で設定された参照キーは、引き続く順呼出しのREAD文のためにも使われる。
- START文の実行中に無効キー条件が発生すると、ファイル名-1の入出力状態に無効キー条件を示す値が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- START文の実行中に例外条件が発生しなかった場合、ファイル名-1の入出力状態が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- END-START指定は、START文の範囲を区切りる。
- ファイル名-1に関連するファイルのLOCK MODE句にAUTOMATICを指定した場合、START文を実行すると、存在するレコードのロックが解除される。
- KEY指定の記述に従って、ファイル名-1のファイルに存在するレコードのキーと、以下のデータ項目が比較される。
- KEY指定を書いた場合、データ名-1のデータ項目が比較される。
- KEY指定を省略した場合、ファイル名-1のRECORD KEY句に書いたデータ項目が比較される。KEY指定の比較演算子には“IS EQUAL TO”を書いたものとみなされる。
- 12.の比較は、文字の大小順序に従って昇順に並んでいる、ファイル内のレコードの参照キーに対して行われる。作用対象の長さが異なる場合、長い方の右側が短い方と同じ長さになるように切り捨てられ、文字比較が行われる。比較の結果、以下の処理が行われます。
- ファイル位置指示子は、比較条件を満足する最初のレコードの示す値に設定される。
- ファイル中のどのレコードも上記の条件を満足しない場合、無効キー条件が発生し、START文の実行は不成功になる。
6.6.7 WRITE文
レコードのファイルへの書き出しを行う。
書き方1
順ファイル
WRITE レコード名-1 [ FROM { 一意名-1 | 定数-1 } ]
[ END-WRITE ]
書き方2
相対・索引ファイル
WRITE レコード名-1 [ FROM { 一意名-1 | 定数-1 } ]
[ INVALID KEY 無条件文-1 ]
[ NOT INVALID KEY 無条件文-2 ]
[ END-WRITE ]
構文規則
- レコード名-1は、データ部のファイル節で定義したレコードの名前でなければならない。レコード名-1は、ファイル名で修飾することができる。
- 一意名-1にデータ項目を指定する場合、レコード名-1の領域と一意名-1の領域は同じであってはならない。一意名-1に関数一意名を指定する場合、英数字関数でなければならない。
- レコード名-1に関連するファイルに関連するUSE AFTER STANDARD EXCEPTION手続きを書かない場合、INVALID KEY指定を書かなければならない。
一般規則
順ファイルの規則
- レコード名-1に関連するファイルは、WRITE文を実行する前に出力モードまたは拡張モードで開いておかなければならない。
- WRITE文を実行しても、ファイル位置指示子は変更されない。
相対・索引に共通する規則
- レコード名-1に関連するファイルは、WRITE文を実行する前に出力モード、入出力両用モードまたは拡張モードで開いておかなければならない。
- WRITE文の実行中に無効キー条件が発生すると、WRITE文の実行は不成功になる。レコード名-1に関連するファイルのレコード領域は変更されない。レコード名-1に関連するファイルの入出力状態に無効キー条件を示す値が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- WRITE文の実行中に無効キー条件以外の例外条件が発生すると、レコード名-1に関連するファイルの入出力状態が設定された後、“INVALID KEY指定”の規則に従って制御が移る。
- WRITE文の実行中に無効キー条件もその他の例外条件も発生しなかった場合、以下の処理が順に行われる。
- レコード名-1に関連するファイルの入出力状態が設定される。
- レコードが書き出される。
- “INVALID KEY指定”の規則に従って制御が移る。
- 拡張モードかつ共用モードで開いたファイルに対し、2つ以上のファイル結合子に対するWRITE文の実行によってレコードが追加される場合、追加されるレコードの並びは、規定されない。
- レコード名-1に関連するファイル管理記述項のLOCK MODE句にAUTOMATICを指定した場合、WRITE文の実行が成功すると、存在するレコードのロックが解除される。
すべてに共通する規則
- WRITE文の実行が成功すると、レコード名-1のレコードはレコード領域で使用不可能になる。ただし、入出力管理段落のSAME RECORD AREA句にレコード名-1に関連するファイルを指定した場合、WRITE文によってレコードが使用不可能になることはない。レコード名-1のレコードは、そのプログラムで使用可能である。
- FROM指定付きのWRITE文の実行結果は、以下に示す文をこの順で実行した結果と同じである。
- MOVE文の規則に従った以下の文
MOVE { 一意名-1 | 定数-1 } TO レコード名-1 - FROM指定のない同じWRITE文
- WRITE文の実行が完了した後、SAME RECORD AREA句にレコード名-1に関連するファイルを指定している場合を除いてレコード名-1の領域の情報は使用不可能になる。ただし、一意名-1の領域の情報は使用可能である。
- WRITE文を実行すると、レコード名-1に関連するファイルの入出力状態の値が更新される。
- WRITE文を実行するとレコードが入出力管理システムに渡される。
- レコード名-1のレコード中の文字位置の個数は、レコード名-1に関連するファイルの最大レコード長より大きくてはならない。また、レコード名-1のレコード中の文字位置の個数は、レコード名-1に関連するファイルの最小レコード長より小さくてはならない。これらの条件を満足しない場合、WRITE文の実行は不成功になり、レコードは書き出されない。このとき、レコード名-1に関連するファイルのレコード領域は変更されない。レコード名-1に関連するファイルの入出力状態には、この状態の原因を示す値が設定される。
相対ファイルの規則
- WRITE文を実行しても、ファイル位置指示子は変更されない。
- 出力モードで開いた順呼出し法のファイルに対してWRITE文を実行すると、相対レコード番号が自動的に設定され、レコード名-1のレコードが書き出される。相対レコード番号は、最初のレコードから順に、1、2、3、…というように設定される。レコード名-1に関連するファイルのACCESS MODE句にRELATIVE KEY指定を書いた場合、書き出されたレコードの相対レコード番号が、入出力管理システムによって、相対キー項目に設定される。
- 出力モードで開いた乱呼出し法のファイル、または出力モードで開いた動的呼出し法のファイルに対してWRITE文を実行する場合、WRITE文を実行する前に、書き出すレコードの相対レコード番号を、相対キー項目に設定しなければならない。
- 拡張モードで開いたファイルに対してWRITE文を実行する場合、そのファイルは順呼出し法のファイルでなければならない。WRITE文を実行すると、レコード名-1のレコードがファイルに追加される。最初のWRITE文のレコードの相対レコード番号は、そのファイルに存在する最大の相対レコード番号より1つ大きい値である。それに続いて書き出されるレコードは、連続的に大きくなる相対レコード番号を持つ。レコード名-1に関連するファイルのACCESS MODE句にRELATIVE KEY指定を書いた場合、書き出されたレコードの相対レコード番号が、相対キー項目に設定される。
- 入出力両用モードで開いたファイルに対してWRITE文を実行する場合、そのファイルは乱呼出し法または動的呼出し法のファイルでなければならない。また、WRITE文を実行する前に、書き出すレコードの相対レコード番号を、相対キー項目に設定しなければならない。WRITE文を実行すると、レコード名-1のレコードがファイルに挿入される。
- 以下の場合、無効キー条件が発生する。
- 乱呼出し法または動的呼出し法のファイルに対するWRITE文の場合、相対キー項目の値と一致するレコードが、ファイルの中に存在する場合。
- 外部で明または暗に定義されたファイルの区域を超えてレコードを書き出そうとした場合。
- 相対レコード番号の有効桁数が、相対キー項目の大きさより大きい場合。
索引ファイルの規則
- WRITE文を実行しても、ファイル位置指示子は変更されない。ただし、以下の場合、ファイル位置指示子は不定になる。
- レコード名-1に関連するファイルのRECORD KEY句にDUPLICATES指定を書いた場合。
- WRITE文を実行する前に、必要な値を主レコードキー項目に設定しなければならない。
- レコード名-1に関連するファイルのRECORD KEY句にDUPLICATES指定を書かなかった場合、主レコードキー項目に設定する値は、ファイル中のすべてのレコードをとおして一意でなければならない。RECORD KEY句にDUPLICATES指定を書いた場合は、主レコードキー項目に設定する値は一意である必要はない。
- WRITE文を実行すると、レコード名-1のレコード領域の内容が書き出される。入出力管理システムは、任意のレコードキーに基づいて後でレコードを呼び出せるようにするために、レコードキー項目の内容を使う。
- 順呼出し法のファイルにレコードを書き出す場合、以下の規則に従って主レコードキー項目に値を設定しなければならない。
- ファイルを出力モードで開いた場合
RECORD KEY句にDUPLICATES指定を書かなかった場合、主レコードのキー項目の大小順序に従って主レコードキーの値が昇順になるように、主レコードキー項目の値を設定しなければならない。RECORD KEY句にDUPLICATES指定を書いた場合は、直前に書き出したレコードの主レコードキーの値と同じ値を設定することもできる。 - ファイルを拡張モードで開いた場合
RECORD KEY句にDUPLICATES指定を書かなかった場合、主レコードキー項目に、ファイル中にある最大の主レコードキーの値より大きい値を設定しなければならない。RECORD KEY句にDUPLICATES指定を書いた場合は、ファイル中にある最大の主レコードキーの値と同じ値を設定することもできる。
- 乱呼出し法または動的呼出し法のファイルにレコードを書き出す場合、任意の順序でレコードを書き出すことができる。
- レコード名-1に関連するファイルのALTERNATE RECORD KEY句にDUPLICATES指定を書いた場合、副レコードキー項目の値は、そのファイル中のすべてのレコードをとおして一意である必要はない。この場合、NEXT指定付きのREAD文で、レコードを書き出した順にレコードを読むことができるように、レコードが格納される。
- 以下の場合、無効キー条件が発生する。
- DUPLICATES指定なしのRECORD KEY句を指定した順呼出し法のファイルに対するWRITE文で、主レコードキーの値が直前のレコードの主レコードキーの値と同じか小さい場合。
- DUPLICATES指定付きのRECORD KEY句を指定した順呼出し法のファイルに対するWRITE文で、主レコードキーの値が直前のレコードの主レコードキーの値より小さい場合。
- DUPLICATES指定なしのRECORD KEY句を指定した乱呼出し法または動的呼出し法のファイルに対するWRITE文で、主レコードキーの値がファイル中に既に存在するレコードの主レコードキーの値と同じ場合。
- DUPLICATES指定なしのALTERNATE RECORD KEY句を指定した乱呼出し法または動的呼出し法のファイルに対するWRITE文で、副レコードキーの値がファイル中に既に存在するレコードの副レコードキーの値と同じ場合。
- 外部で明または暗に定義されたファイルの区域を超えてレコードを書き出そうとした場合。
6.6.8 USE文
入出力誤り処理手続きの開始を指定する。
書き方
USE [ GLOBAL ] AFTER STANDARD { EXCEPTION | ERROR } PROCEDURE ON
{ {ファイル名-1} … | INPUT | OUTPUT | I-O | EXTEND }
(※) SIT COBOLは、GLOBAL句を指定することはできない。
構文規則
- USE文は、手続き部の宣言部分の節の見出しに続けて書かなければならない。USE文は、1つのUSE文だけで完結文でなければならない。USE文の後に、USE手続きを定義するいくつかの段落を書く。USE手続き段落は、省略することもできる。なお、ここでは、USE AFTER STANDARD EXCEPTION手続きを、「USE手続き」と略記する。
- 2つ以上のUSE文に、ファイル名-1に同じファイル名を指定することによって、複数のUSE手続きが同時に実行されることがあってはならない。
- EXCEPTIONとERRORは同義語である。
- ファイル名-1の並びに、ORGANIZATION句の指定が異なるファイルまたはACCESS MODE句の指定が異なるファイルを指定することもできる。また、ORGANIZATION句の指定が異なるファイルまたはACCESS MODE句の指定が異なるファイルを、USE文で暗に参照することもできる。
- INPUT指定、OUTPUT指定、I-O指定またはEXTEND指定を書いたUSE文は、1つの手続き部の宣言部分では、それぞれただ1つだけ書くことができる。
一般規則
- USE文は、USE手続きを実行する条件を指定する。USE文自身は実行されない。
- USE手続きは、AT
END指定(順ファイル、相対ファイル、索引ファイル)またはINVALID KEY
指定(相対ファイルまたは索引ファイル)が優先する場合を除いて、入出力文(暗黙に実行される入出力文も含む)の実行が不成功になったときに実行される。
USE手続きを実行する条件は、以下のように指定する。
- ファイル名-1指定は、ファイル名-1に対する入出力文の実行が不成功になったときにUSE手続きを実行することを指定する。
- INPUT指定は、入力モードで開かれているファイルに対する入出力文の実行中、または入力モードでファイルを開く処理が不成功になったときにUSE手続きを実行することを指定する。
- OUTPUT指定は、出力モードで開かれているファイルに対する入出力文の実行中、または出力モードでファイルを開く処理が不成功になったときにUSE手続きを実行することを指定する。
- I-O指定は、入出力両用モードで開かれているファイルに対する入出力文の実行中、または入出力両用モードでファイルを開く処理が不成功になったときにUSE手続きを実行することを指定する。
- EXTEND指定は、拡張モードで開かれているファイルに対する入出力文の実行中、または拡張モードでファイルを開く処理が不成功になったときにUSE手続きを実行することを指定する。
- 宣言節は、一番外側のプログラムおよび内部プログラムのどのプログラムにも書くことができる。
- 入れ子のプログラムで入出力文の実行が不成功になったときに実行される宣言節は、以下の規則をこの順に適用することによって選択される。条件を満足するUSE文が見つかった場合、それに続くUSE手続きだけが実行される。
- 不成功になった入出力文を書いたプログラムの中の、条件を満足するUSE文。
- 不成功になった入出力文を書いたプログラムを直接または間接に含むプログラム中のGLOBAL指定を書いたUSE文で、条件を満足するUSE文。該当するUSE文が2つ以上ある場合は、最も内側のプログラムの中のUSE文。
- USE文に指定した条件は、USE文を含む翻訳単位のプログラムが実行されているときに検査される。別の翻訳単位に書いたUSE文の条件は検査されない。
- USE手続きの中から手続き部分の手続きを参照してはならない。
- 宣言節の節名およびUSE手続きの段落名を、別の宣言節または手続き部分の手続きで参照する場合、PERFORM文によって参照しなければならない。
- USE文にファイル名-1を書いた場合、他のUSE文に書いた条件は、ファイル名-1に対して適用されない。
- USE手続きの実行後、入出力状態が重大誤りでなければ、USE手続きを実行させた入出力文の次の実行文に制御が移る。
- USE手続きの実行が終了する前に、その手続きを再び実行させる可能性のある文を実行することはできない。
6.7 整列併合
6.7.1 MERGE文
2つ以上のファイルを併合する。
一般形式
MERGE ファイル名-1
ON { ASCENDING | DESCENDING } KEY { データ名-1 } …
[ COLLATING SEQUENCE IS 符号系名-1 ]
USING ファイル名-2 { ファイル名-3 } …
{ OUTPUT PROCEDURE IS 手続き名-1 [ { THROUGH | THRU } 手続き名-2 ] |
GIVING { ファイル名-4 } … }
(※) SIT COBOLは、符号系名-1には対応していない。(制限事項)
(※) SIT
COBOLは、GIVING句に複数のファイルを指定することはできない。(制限事項)
構文規則
- ファイル名-1は、データ部の整列併合用ファイル記述項で定義しなければならない。
- ファイル名-2およびファイル名-3は、以下の規則に従わなければならない。
- ファイル名-1のレコード形式が可変長の場合、ファイル名-2およびファイル名-3のレコードの長さは、ファイル名-1の最小レコード長以上かつ最大レコード長以下でなければならない。(*1)
- ファイル名-1のレコード形式が固定長の場合、ファイル名-2およびファイル名-3のレコードの長さは、ファイル名-1のレコード長以下でなければならない。
- データ名-1は、以下の規則に従わなければならない。
- データ名-1は、ファイル名-1のレコード記述項で定義したデータ項目でなければならない。
- データ名-1は、修飾することができる。
- データ名-1に、可変反復データ項目を従属する集団項目を指定してはならない。
- ファイル名-1に2つ以上のレコード記述項を書いた場合、データ名-1の並びには、1つのレコード記述項に書いたデータ項目を指定しなければならない。1つのレコード記述項のデータ名-1のデータ項目と同じ文字位置が、そのファイルのすべてのレコード中のキーとみなされる。
- データ名-1に、OCCURS句を指定したデータ項目またはOCCURS句を指定したデータ項目に従属するデータ項目を指定することはできない。
- ファイル名-1のレコード形式が可変長の場合、データ名-1のデータ項目は、ファイル名-1の最小レコードの大きさの範囲内に含まれていなければならない。
- ファイル名-2、ファイル名-3およびファイル名-4は、データ部中の整列併合用ファイル記述項以外のファイル記述項で定義しなければならない。
- ファイル名-1~ファイル名-4に、同じファイルを指定することはできない。
- ファイル名-1~ファイル名-4のいくつかの組を、1つのSAME AREA句、または1つのSAME SORT/SORT-MERGE AREA句に指定することはできない。しかし、1つのSAME RECORD AREA句には、ファイル名-4のいくつかの組を指定することができる。(*2)
- THROUGHとTHRUは同義語である。
- ファイル名-4に索引ファイルを指定する場合、以下の規則に従わなければならない。
- 最初のKEY指定は、ASCENDING KEY指定でなければならない。
- 最初のデータ名-1に指定したデータ項目のレコード内文字位置は、索引ファイルの主レコードキーに関連付けたデータ項目のレコード内文字位置と同じでなければならない。また、2つのデータ項目は同じ長さでなければならない。
- ファイル名-4は、以下の規則に従わなければならない。
- ファイル名-4のレコード形式が可変長の場合、ファイル名-1のレコードの長さは、ファイル名-4の最小レコード長以上かつ最大レコード長以下でなければならない。(*1)
- ファイル名-4のレコード形式が固定長の場合、ファイル名-1のレコードの長さは、ファイル名-4のレコード長以下でなければならない。
- 符号系名-1は、特殊名段落のALPHABET句で機能名に対応付けた符号系名であってはならない。
- ファイル名-2~ファイル名-4は、以下のファイルでなければならない。
- 大記憶装置の順ファイル
- 順呼出し法の相対ファイル
- 順呼出し法の索引ファイル
(*1) SIT
COBOLは、可変長ファイルには対応していない。(制限事項)
(*2) SIT
COBOLは、SAME AREA句、SAME-SORT/SAME-MERGE
AREA句には対応していない。(制限事項)
一般規則
MERGE文の全般規則
- ファイル名-2およびファイル名-3のレコードは、ASCENDING KEY指定またはDESCENDING KEY指定に従って並んでいなければならない。その順序で並んでいない場合、MERGE文の結果は規定されない。
- MERGE文を実行すると、以下の処理が行われる。
- ファイル名-2およびファイル名-3に対してREAD文が実行され、READ文によって読み込まれたレコードが、併合操作に引き渡される。この段階を始める前に、ファイル名-2およびファイル名-3のファイルは開いた状態であってはならない。この段階の中で、ファイル名-2およびファイル名-3のファイルは自動的にオープンされ、クローズされる。ここでの処理を、「併合操作の最初の段階」という。
- ファイル名-2およびファイル名-3の中のすべてのレコードが併合される。ここでの処理を、「併合操作」という。
- 以下の処理によって、併合されたレコードがファイル名-1のレコードとして使用可能になる。ここでの処理を、「併合操作の最後の段階」という。
OUTPUT PROCEDURE指定を書いた場合、出力手続きが実行される。「出力手続き」とは、手続き名-1に書いた手続き、または手続き名-1から手続き名-2までに書いた手続きのことである。出力手続きの中でファイル名-1のファイルに対するRETURN文を実行すると、ファイル名-1のレコードが使用可能になる。
GIVING指定を書いた場合、併合されたレコードがファイル名-1のレコードとして使用可能になり、ファイル名-4のファイルに書き出される。この段階を始める前に、ファイル名-4のファイルは、開いた状態であってはならない。この段階の中で、ファイル名-4のファイルは自動的にオープンされ、クローズされる。
- 併合操作の最初の段階では、以下の処理が順に行われる。
- 初期処理が行われる。これは、ファイル名-2およびファイル名-3のファイルに対して、INPUT指定のOPEN文を実行したことと同じである。OUTPUT PROCEDURE指定を書いた場合、初期処理は、出力手続きに制御が移る前に行われる。
- ファイル名-2およびファイル名-3のレコードが、併合操作に引き渡される。これは、ファイル名-2およびファイル名-3に対して、NEXT指定およびAT END指定のREAD文を、レコードがなくなるまで実行したことと同じである。
- 終了処理が行われる。これは、ファイル名-2またはファイル名-3だけを指定したCLOSE文を実行したことと同じである。OUTPUT
PROCEDURE指定を書いた場合、終了処理は、出力手続きの最後の文に制御が渡った後まで行われない。
上記のa.~c.の処理の中で、ファイル名-2~ファイル名-4のファイルに関連するUSE AFTER STANDARD EXCEPTION手続きが実行されることがある。そのUSE手続きの中では、ファイル名-2~ファイル名-4のファイルを操作する文、またはそれらのファイル中のレコードを参照する文を実行することはできない。(*1)
- ファイル名-1のレコード形式が固定長で、ファイル名-2およびファイル名-3のレコードがファイル名-1のレコード長より短い場合、そのレコードがファイル名-1のファイルに引き渡されるとき、レコードの右側の余りの部分には空白が詰められる。
- データ名-1のデータ項目を、「キー項目」という。キー項目を2つ以上指定する場合、キーの強さの順に左から右へ並べる。
- ASCENDING指定を書いた場合、ファイル名-2およびファイル名-3のレコードのキー項目の値が比較の規則に従って比較され、キー項目の値が小さいレコードから大きいレコードの順に併合される。
- DESCENDING指定を書いた場合、ファイル名-2およびファイル名-3のレコードのキー項目の値が比較の規則に従って比較され、キー項目の値が大きいレコードから小さいレコードの順に併合される。
- 5.の比較の結果、すべてのキー項目の内容が同じであるレコードが2つ以上存在する場合には、ファイル名-2およびファイル名-3の並びを書いた順に各ファイル中のレコードが引き取られる。1つのファイル名-2またはファイル名-3のファイル中にそのような複数のレコードが存在する場合、他のファイルからレコードが引き取られる前にレコードが引き取られる。
- 文字比較の規則が適用される場合、キー項目の値の大小順序は、以下の規則に従って決定される。
- COLLATING SEQUENCE指定を書いた場合、符号系名-1に対応付けた文字の大小順序に従う。
- COLLATING SEQUENCE指定を省略した場合には、見出し部の翻訳用計算機段落にPROGRAM COLLATING SEQUENCE句を書いた場合、その句で指定した文字の大小順序に従う。この句を省略した場合、計算機固有の文字の大小順序に従う。
OUTPUT PROCEDURE指定の規則
- OUTPUT PROCEDURE指定を書いた場合、併合操作が終了した後、出力手続きに制御が移る。出力手続きの最後の文を実行した後、MERGE文の次の実行文に制御が移る。
- 出力手続きに制御が移ったとき、ファイル名-1のレコードは完全に併合されていて、RETURN文によって順番に引き取れるような状態になっている。出力手続きの中には、ファイル名-1のファイルに対するRETURN文を書く。RETURN文は、併合操作の最後の段階から、1つのレコードを引き取る。
- 出力手続きの中で実行される文を、出力手続きの範囲という。出力手続きの範囲は、以下のとおりである。
- 出力手続きの中に書いた文。
- 出力手続きの中に書いた文(たとえばCALL文など)によって制御が移行した結果、実行されるすべての文。
- 出力手続きの中に書いた文によって実行される宣言手続きの中のすべての文。
- 出力手続きの範囲で、MERGE文、RELEASE文またはSORT文を実行することはできない。
- 出力手続きの範囲で、MERGE文と同じ手続き部内に書かれたEXIT PROGRAM文を実行することはできない。
GIVING指定の規則
- GIVING指定を書いた場合、併合操作が終了した後、ファイル名-1のすべてのレコードが、ファイル名-4のファイルに移される。
- MERGE文を実行する前に、ファイル名-4のファイルは開かれた状態であってはならない。
- ファイル名-4の各ファイルに対して、以下の処理が順に行われる。
- 初期処理が行われる。これは、ファイル名-4のファイルに対して、OUTPUT指定のOPEN文を実行したことと同じである。
- ファイル-1のレコードを併合操作から引き取る。これは、ファイル名-1のファイルに対して、レコード名だけを指定したWRITE文を、ファイル名-1のレコードがなくなるまで実行したことと同じである。
ファイル名-4に相対ファイルを指定した場合、引き取られる相対レコード番号は、最初のレコードから順に、1、2、3、…というように設定される。ファイル名-4のファイルに相対キー項目を指定した場合、レコードが引き取られるごとに、相対レコード番号が相対キー項目に設定される。MERGE文の実行後の相対キー項目の内容は、ファイル名-4のファイルに引き取られた最後のレコードを表す。 - 終了処理が行われる。これは、ファイル名-4だけを指定したCLOSE文を実行したことと同じである。
上記のa.~c.の処理の中で、ファイル名-4に関連するUSE AFTER STANDARD EXCEPTION手続きが実行されることがある。そのUSE手続きの中では、ファイル名-4のファイルを操作する文またはファイル名-4のレコードを参照する文を実行することはできない。(*1)
- ファイル名-4のファイルの外部で定義された区域を超えて、最初にレコードを書き出そうとすると、以下の処理が行われる。(*1)
- ファイル名-4に関連するUSE AFTER STANDARD EXCEPTION手続きを書いた場合、そのUSE手続きが実行される。そして、USE手続きから制御が戻った後、ファイル名-4だけを指定したCLOSE文を実行したかのように、終了処理が行われる。
- ファイル名-4に関連するUSE AFTER STANDARD EXCEPTION手続きを書かなかった場合、ファイル名-4だけを指定したCLOSE文を実行したかのように、終了処理が行われる。
- ファイル名-4のレコード形式が固定長で、ファイル名-1のレコードの長さがファイル名-4のレコード長より短い場合、そのレコードがファイル名-4のファイルに引き取られるとき、レコードの右側の余りの部分には空白が詰められる。
(*1) SIT COBOLでは、USE AFTER STANDARD EXCEPTION手続きが書かれていても、実行されることはない。(制限事項)
マージ例
USING/GIVINGを利用した例と、USING/OUTPUT PROCEDUREを使用した例を示す。
(サンプル: MERGE文.cob)
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. MERGE_01.
000020 ENVIRONMENT DIVISION.
000030 INPUT-OUTPUT SECTION.
000040 FILE-CONTROL.
000050 SELECT F1 ASSIGN TO "F1.txt". *> MERGEの入力と出力に使用
000060 SELECT F2 ASSIGN TO "F2.txt". *> MERGEの入力に使用
000070 SELECT MERGE-F ASSIGN TO "SD1". *> "SD1"はメモのみである
000080 DATA DIVISION.
000090 FILE SECTION.
000100 FD F1.
000110 01 F1-REC.
000120 02 F1-DATA1 PIC X(5).
000130 02 F1-DATA2 PIC S9(3)V9(2).
000140 02 F1-DMY PIC X(10).
000150*
000160 FD F2.
000170 01 F2-REC.
000180 02 F2-DATA1 PIC X(5).
000190 02 F2-DATA2 PIC S9(3)V9(2).
000200 02 F2-DMY PIC X(10).
000210*
000220 SD MERGE-F.
000230 01 MERGE-R.
000240 02 DATA1 PIC X(5). *> マージキー1: 英数字項目
000250 02 DATA2 PIC S9(3)V9(2). *> マージキー2: 数字項目
000260 02 PIC X(10).
000270 WORKING-STORAGE SECTION.
000280 01 WK1. *> マージ用データ1
000290 02 PIC X(20) VALUE "aaaaa,+33, ".
000300 02 PIC X(20) VALUE "aaaaa, 22.12, ".
000310 02 PIC X(20) VALUE "bbbbb,+100, ".
000320 02 PIC X(20) VALUE "bbbbb,-100.00,".
000330 02 PIC X(20) VALUE "ccccc, 123, ".
000340 02 PIC X(20) VALUE "ccccc,-123, ".
000350 02 PIC X(20) VALUE "ddddd,-444.4, ".
000360 02 PIC X(20) VALUE "fffff,-123, ".
000370 02 PIC X(20) VALUE "ggggg, 001, ".
000380 02 PIC X(20) VALUE "zzzzz, 001, ".
000390 01 WK1-RE REDEFINES WK1.
000400 02 W1-DATA PIC X(20) OCCURS 10.
000410 01 WK2. *> マージ用データ2
000420 02 PIC X(20) VALUE "aaaaa, 22.12, ,".
000430 02 PIC X(20) VALUE "bbbbb,+200, ,".
000440 02 PIC X(20) VALUE "ccccc, 50, ,".
000450 02 PIC X(20) VALUE "ccccc,-123, ,".
000460 02 PIC X(20) VALUE "ddddd, 333, ,".
000470 02 PIC X(20) VALUE "fffff, -50, ,".
000480 02 PIC X(20) VALUE "fffff,-200, ,".
000490 02 PIC X(20) VALUE "fffff,-300, ,".
000500 02 PIC X(20) VALUE "ggggg, 0, ,".
000510 02 PIC X(20) VALUE "yyyyy, 0, ,".
000520 01 WK2-RE REDEFINES WK2.
000530 02 W2-DATA PIC X(20) OCCURS 10.
000540 01 I PIC 9(2).
000550 PROCEDURE DIVISION.
000560 MAIN00.
000570* USING句およびGIVING句を使用する例
000580 DISPLAY "*** MERGE USING/GIVING (F1->F2)".
000590 PERFORM データの準備.
000600 DISPLAY "併合前のデータ".
000610 PERFORM データの表示F1.
000620 PERFORM データの表示F2.
000630* マージの実行
000640 MERGE MERGE-F
000650 ASCENDING DATA1 *> DATA1は昇順にマージする
000660 DESCENDING DATA2 *> DATA2は降順にマージする
000670 USING F1 F2
000680 GIVING F1.
000690 DISPLAY "併合後のデータ".
000700 PERFORM データの表示F1.
000710 DISPLAY "".
000720* INPUT USING/OUTPUT PROCEDUREを使用する例
000730 DISPLAY "*** MERGE USING / OUTPUT PROCEDURE".
000740 PERFORM データの準備.
000750 DISPLAY "併合前のデータ".
000760 PERFORM データの表示F1.
000770 PERFORM データの表示F2.
000780 MERGE MERGE-F
000790 ASCENDING DATA1 *> DATA1は昇順にマージする
000800 DESCENDING DATA2 *> DATA2は降順にマージする
000810 USING F1 F2
000820 OUTPUT PROCEDURE マージ済データの受け取り.
000830 DISPLAY "併合後のデータ".
000840 PERFORM データの表示F1.
000850 STOP RUN.
000860*============================================================
000870 データの準備.
000880 OPEN OUTPUT F1.
000890 PERFORM VARYING I FROM 1 UNTIL I > 10
000900 UNSTRING W1-DATA(I) *> W1-DATA(I)を','で分離しF1-DATA1、F1-DATA2、F1-DMYに設定
000910 DELIMITED BY ","
000920 INTO F1-DATA1, F1-DATA2
000930 MOVE ALL "-" TO F1-DMY
000940 WRITE F1-REC
000950 END-PERFORM.
000960 CLOSE F1.
000970*
000980 OPEN OUTPUT F2.
000990 PERFORM VARYING I FROM 1 UNTIL I > 10
001000 UNSTRING W2-DATA(I) *> W2-DATA(I)を','で分離しF2-DATA1、F2-DATA2、F2-DMYに設定
001010 DELIMITED BY ","
001020 INTO F2-DATA1, F2-DATA2
001030 MOVE ALL "+" TO F2-DMY
001040 WRITE F2-REC
001050 END-PERFORM.
001060 CLOSE F2.
001070*-----------------------------------------------------------
001080 データの表示F1.
001090 DISPLAY "F1 DATA".
001100 OPEN INPUT F1.
001110 PERFORM FOREVER
001120 READ F1 *> F1よりデータの読込み
001130 AT END
001140 EXIT PERFORM
001150 END-READ
001160 DISPLAY F1-REC *> READしたデータの表示
001170 END-PERFORM
001180 CLOSE F1.
001190*
001200 データの表示F2.
001210 DISPLAY "F2 DATA".
001220 OPEN INPUT F2.
001230 PERFORM FOREVER
001240 READ F2 *> F2よりデータの読込み
001250 AT END
001260 EXIT PERFORM
001270 END-READ
001280 DISPLAY F2-REC *> READしたデータの表示
001290 END-PERFORM
001300 CLOSE F2.
001310*-----------------------------------------------------------
001320 マージ済データの受け取り
001330* マージ済のデータを受け取り、F1に書き出す
001340 OPEN OUTPUT F1.
001350 PERFORM FOREVER
001360 RETURN MERGE-F *> RETURN文によるデータの受け取り
001370 AT END
001380 EXIT PERFORM
001390 END-RETURN
001400 WRITE F1-REC FROM MERGE-R *> 受け取ったデータの書き出し
001410 END-PERFORM.
001420 CLOSE F1.MERGE文の実行は、大きく3つのフェーズに分かれる。
1つ目のフェーズは、ソートワーク(マージ対象のデータを溜め込む領域)へのデータの引き渡しである。このフェーズを「併合操作の最初の段階」という。
2つ目のフェーズは、そのソートワーク上のデータのマージである。このフェーズを「併合操作」という。
そして、3つ目のフェーズは、ソートされたソートワーク上のデータの受け取りである。このフェーズを「併合操作の最後の段階」という。
以下、簡単に上記のプログラムの説明をする。
マージするデータは、WK1、WK2として用意されており、この例ではCSV形式(カンマ区切り)のデータとなっている。(000280-000380行および000410-000510行)
「データの準備」段落(000870-001060行)では、これらのWK1およびWK2をファイルF1,
F2に書き込むため、UNSTRING文を使ってW-DATAの各要素を、カンマ(,)で区切り、それをF1のレコード領域のF1-DATA1、F1-DATA2に設定し(F2の場合はレコード領域F2-DATA1、F2-DATA2に設定し)、さらにF1-DMYにALL
“+”を設定し、それからWRITE文で出力している。
最初のMERGE文(000640-000680行)では、USING句にF1、F2が指定されているので、1フェーズ目で、そのF1、F2のデータをソートワークに引き渡す。
なお、入力データであるF1、F2は、ASCENDING/DESCENDING KEYで指定した順にあらかじめ整列されていなければならず、そのため、F1、F2の生成データであるWK1、WK2は、その順序に並んでいることに注意されたい。
次に2フェーズ目でソートワーク上のデータをマージする。これはSIT
COBOLの中で行われるので、特に何もしなくてよい。最後に3フェーズ目で、GIVING句に指定されたファイルF1にデータを受け渡す。
マージキーは、1-5桁目のデータDATA1がASCENDING指定なので昇順、6-10桁目のデータDATA2がDESCENDINGなので降順で指定されている。指定されたキー順にマージされるので、まずは、DATA1の昇順にレコードを並べ、DATA1の値が同じレコードでは、DATA2の値が降順となるように並ぶ。
もし、キーの順序を、DESCENDING
DATA2 ASCENDING
DATA1としたら、まずはDATA2の降順にレコードを並べ、さらにDATA1の昇順にレコードを並べることになるので、全く異なるマージ結果となる。
2つ目のMERGE文(000780-820行)では、1フェーズ目で、USING句にF1、F2が指定されているので、1フェーズ目で、そのF1、F2のデータをソートワークに引き渡す。
そして2フェーズ目で、ソートワーク上のデータがマージされ、3フェーズ目で、今度は、OUTPUT
PROCEDUREに指定された「マージ済データの受け取り」段落(001340-001420行)が実行され、その中のRETURN文で、ソートワークの中のデータを1つ1つ受け取る。受け取ったレコードは、F1に書き出している。
実行したときの出力結果は次のとおりである。
*** MERGE USING/GIVING (F1->F2)
併合前のデータ
F1 DATA
aaaaa03300----------
aaaaa02212----------
bbbbb10000----------
bbbbb1000p----------
ccccc12300----------
ccccc1230p----------
ddddd4444p----------
fffff1230p----------
ggggg00100----------
zzzzz00100----------
F2 DATA
aaaaa02212++++++++++
bbbbb20000++++++++++
ccccc05000++++++++++
ccccc1230p++++++++++
ddddd33300++++++++++
fffff00000++++++++++
fffff2000p++++++++++
fffff3000p++++++++++
ggggg00000++++++++++
yyyyy00000++++++++++
併合後のデータ
F1 DATA
aaaaa03300----------
aaaaa02212----------
aaaaa02212++++++++++
bbbbb20000++++++++++
bbbbb10000----------
bbbbb1000p----------
ccccc12300----------
ccccc05000++++++++++
ccccc1230p----------
ccccc1230p++++++++++
ddddd33300++++++++++
ddddd4444p----------
fffff00000++++++++++
fffff1230p----------
fffff2000p++++++++++
fffff3000p++++++++++
ggggg00100----------
ggggg00000++++++++++
yyyyy00000++++++++++
zzzzz00100----------
*** MERGE USING / OUTPUT PROCEDURE
併合前のデータ
F1 DATA
aaaaa03300----------
aaaaa02212----------
bbbbb10000----------
bbbbb1000p----------
ccccc12300----------
ccccc1230p----------
ddddd4444p----------
fffff1230p----------
ggggg00100----------
zzzzz00100----------
F2 DATA
aaaaa02212++++++++++
bbbbb20000++++++++++
ccccc05000++++++++++
ccccc1230p++++++++++
ddddd33300++++++++++
fffff00000++++++++++
fffff2000p++++++++++
fffff3000p++++++++++
ggggg00000++++++++++
yyyyy00000++++++++++
併合後のデータ
F1 DATA
aaaaa03300----------
aaaaa02212----------
aaaaa02212++++++++++
bbbbb20000++++++++++
bbbbb10000----------
bbbbb1000p----------
ccccc12300----------
ccccc05000++++++++++
ccccc1230p----------
ccccc1230p++++++++++
ddddd33300++++++++++
ddddd4444p----------
fffff00000++++++++++
fffff1230p----------
fffff2000p++++++++++
fffff3000p++++++++++
ggggg00100----------
ggggg00000++++++++++
yyyyy00000++++++++++
zzzzz00100----------ここで、6-10カラム目(F1-DATA2)は、S9(3)V9(2)
という数字データ項目(外部10進数)なので、5桁の最初の3桁が整数部で、後の2桁が小数部である。また、正負については最後の5桁目(全体の10カラム目)で表現(重ね符号)されている。
上記のデータの中には、5桁目(全体の10カラム目)が’p’となっているものがあるが、これはASCIIコードでは、0x70
であり’7’は負、’0’は下1桁の数字を表している。例えば、’1230p’は、-123.00
を示している。
重ね符号を含むデータの表現方法については、USAGE句で決められている。詳しくは、「データ部のUSAGE句」を参照されたい。
6.7.2 RELEASE文
整列操作の最初の段階にレコードを引き渡す。
一般形式
RELEASE レコード名-1 [ FROM { 一意名-1 | 定数-1 } ]
構文規則
- RELEASE文は、レコード名-1のファイルに対するSORT文で指定した入力手続きの中にだけ書くことができる。
- レコード名-1は、整列併合用ファイル記述項に関連するレコード記述項で定義しなければならない。
- レコード名-1は、ファイル名で修飾することができる。
- 一意名-1にデータ項目を指定する場合、レコード名-1の記憶領域と一意名-1の記憶領域は、同じであってはならない。一意名-1に関数一意名を指定する場合、一意名-1は英数字関数でなければならない。
一般規則
- RELEASE文は、レコード名-1のレコードを整列操作の最初の段階に引き渡す。
- RELEASE文を実行すると、レコード名-1のレコードはレコード領域中で使用不可能になる。ただし、入出力管理段落のSAME RECORD AREA句に、レコード名-1に関連するファイルを指定した場合、レコード名-1のレコードは、レコード領域中で使用不可能にならない。そのレコードは、同じSAME RECORD AREA句に指定した他のファイルの出力レコードとして使用可能である。(*1)
- FROM指定付きのRELEASE文の実行結果は、以下の順に2つの文を実行した結果と同じである。
- MOVE { 一意名-1 | 定数-1 } TO レコード名-1
- FROM指定のない同じRELEASE文
(*1) SIT COBOLは、入出力管理段落にSAME RECORD AREA句を指定することはできない。(制限事項)
6.7.3 RETURN文
整列または併合操作の最後の段階から、整列または併合されたレコードを引き取る。
一般形式
RETURN ファイル名-1 RECORD [ INTO 一意名-1 ]
AT END 無条件文-1
[ NOT AT END 無条件文-2 ]
[ END-RETURN ]
構文規則
- RETURN文は、ファイル名-1のファイルに対するSORT文またはMERGE文に指定した出力手続きの中にだけ書くことができる。
- ファイル名-1は、整列併合用ファイル記述項で定義しなければならない。
- 一意名-1の記憶領域とファイル名-1のレコード領域は、同じであってはならない。
一般規則
- RETURN文を実行すると、ファイル名-1のファイルからSORT文またはMERGE文に指定したキーの並びによって決められた次のレコードが引き取られる。次のレコードがない場合、ファイル終了条件が発生する。
- ファイル名-1のレコード記述項に2つ以上のレコードを定義した場合、それらのレコードは再定義の規則に従って同じ記憶領域を共用する。
- INTO指定は、以下の場合に書くことができる。
- ファイル名-1のレコード記述項を1つだけ書いた場合。
- ファイル名-1に関連するレコード名および一意名-1のデータ項目が、すべて集団項目または英数字項目の場合。
- INTO指定を書いた場合、以下の順に処理が行われる。
- INTO指定のない同じRETURN文が実行される。
- a.のRETURN文の実行が成功した場合、現在のレコードが、CORRESPONDING指定なしのMOVE文の規則に従って、ファイル名-1のレコード領域から一意名-1の領域に転記される。読み込まれたレコードは、ファイル名-1のレコード領域と一意名-1のデータ項目の両方で使用可能になる。
現在のレコードの大きさは、ファイル名-1のRECORD句の規則に従って決定される。ファイル名-1のファイル記述項にRECORD VARYING句を書いた場合、b.では集団項目転記が行われる(*1)。一意名-1に付けた添字は、a.の後b.の前に評価される。a.のRETURN文の実行が不成功の場合、暗黙のMOVE文は実行されない。
- ファイル終了条件が発生した場合、RETURN文の実行は不成功になり、ファイル名-1のレコード領域の内容は不定になる。そして、無条件文-1に制御が移り、無条件文-1の実行後、RETURN文の最後に制御が移る。ただし、無条件文-1で制御の明示移行を起こす手続き分岐または条件文を実行した場合、その文の規則に従って制御が移る。無条件文 -1の実行後は、実行中の出力手続きの一部として、RETURN文を実行することはできない。
- RETURN文の実行中にファイル終了条件が発生しなかった場合、以下の処理が順に行われる。
- 引き取られたレコードが、ファイル名-1のレコード領域で使用可能になる。INTO指定を書いた場合、ファイル名-1のレコード領域から一意名-1へレコードが転記される。
- NOT AT END指定を書いた場合、無条件文-2に制御が移る。そして、無条件文-2の実行後、RETURN文の最後に制御が移る。ただし、無条件文-2で制御の明示移行を起こす手続き分岐または条件文を実行した場合、その文の規則に従って制御が移る。NOT AT END指定を省略した場合は、RETURN文の最後に制御が移る。
- END-RETURN指定は、RETURN文の範囲を区切る。
(*1) SIT COBOLは、ファイル名-1のファイル記述項にRECORD VARYING句を書くことはできない。
6.7.4 SORT文(ファイルのソート)
キー項目の値の順にレコードを整列する。
一般形式
SORT ファイル名-1
{ ON { ASCENDING | DESCENDING } KEY { データ名-1 }… }…
[ WITH DUPLICATES IN ORDER ]
[ COLLATING SEQUENCE IS 符号系名-1 ]
{ INPUT PROCEDURE IS 手続き名-1 [ { THROUGH | THRU } 手続き名-2 ] |
USING { ファイル名-2 } … }
{ OUTPUT PROCEDURE IS 手続き名-3 [ { THROUGH | THRU } 手続き名-4 ] |
GIVING { ファイル名-3 } … }
(※) SIT COBOLは、符号系名-1には対応していない。(制限事項)
(※) SIT
COBOLは、DUPLICATS句には対応していない。(制限事項)
(※) SIT
COBOLは、GIVING句に複数のファイルを指定することはできない。(制限事項)
構文規則
- SORT文は、宣言部分を除く手続き部のどこにでも書くことができる。
- ファイル名-1は、データ部の整列併合用ファイル記述項で定義しなければならない。
- ファイル名-2は、以下の規則に従わなければならない。
- ファイル名-1のレコード形式が可変長の場合、ファイル名-2のレコードの長さは、ファイル名-1の最小レコード長以上かつ最大レコード長以下でなければならない。
- ファイル名-1のレコード形式が固定長の場合、ファイル名-2のレコードの長さは、ファイル名-1のレコード長以下でなければならない。
- データ名-1は、以下の規則に従わなければならない。
- データ名-1は、ファイル名-1のレコード記述項で定義したデータ項目でなければならない。
- データ名-1は、修飾することができる。
- データ名-1に、可変反復データ項目を従属する集団項目を指定することはできない。
- ファイル名-1に2つ以上のレコード記述項を書いた場合、データ名-1の並びには、1つのレコード記述項に書いたデータ項目を指定しなければならない。1つのレコード記述項中のデータ名-1のデータ項目と同じ文字位置が、そのファイルのすべてのレコード中のキーとみなされる。
- データ名-1に、OCCURS句を指定したデータ項目またはOCCURS句を指定したデータ項目に従属するデータ項目を指定することはできない
- ファイル名-1のレコード形式が可変長の場合、データ名-1のデータ項目は、ファイル名-1の最小レコードの大きさの範囲内に含まれていなければならない。(*1)
- ファイル名-2およびファイル名-3は、データ部の整列併合用ファイル以外のファイル記述項で定義しなければならない。
- ファイル名-1~ファイル名-3のいくつかの組を、1つのSAME AREA句または1つのSAME SORT/SORT-MERGE AREA句に指定することはできない。また、ファイル名-3のいくつかの組を、1つのSAME句に指定することはできない。(*2)
- THROUGHとTHRUは同義語である。
- ファイル名-3に索引ファイルを指定する場合、以下の規則に従わなければならない。
- 最初のKEY指定は、ASCENDING KEY指定でなければならない。
- 最初のデータ名-1に指定したデータ項目のレコード内文字位置は、索引ファイルの主レコードキーに関連付けたデータ項目のレコード内文字位置と同じでなければならない。また、2つのデータ項目は同じ長さでなければならない。
- ファイル名-3は、以下の規則に従わなければならない。
- ファイル名-3のレコード形式が可変長の場合、ファイル名-1のレコードの長さは、ファイル名-3の最小レコード長以上かつ最大レコード長以下でなければならない。(*1)
- ファイル名-3のレコード形式が固定長の場合、ファイル名-1のレコードの長さは、ファイル名-3のレコード長以下でなければならない。
- 符号系名-1は、特殊名段落のALPHABET句で機能名に対応付けた符号系名であってはならない。
- ファイル名-2およびファイル名-3は、以下のファイルでなければならない。
- 大記憶装置の順ファイル
- 順呼出し法の相対ファイル
- 順呼出し法の索引ファイル
(*1) SIT
COBOLは、ファイル名-1、ファイル名-3として可変長ファイルを指定することはできない。(制限事項)
(*2)
SIT COBOLは、SAME AREA句には対応していない。(制限事項)
一般規則
SORT文の全般規則
- SORT文を実行すると、以下の処理が順に行われる。
- 以下の処理によって、レコードが整列操作に引き渡される。ここでの処理を、「整列操作の最初の段階」という。
INPUT PROCEDURE指定を書いた場合、入力手続きが実行される。「入力手続き」とは、手続き名-1に書いた手続き、または手続き名-1から手続き名-2までに書いた手続きのことである。入力手続きの中でファイル名-1のレコードに対するRELEASE文を実行すると、レコードが整列操作に引き渡される。
USING指定を書いた場合、ファイル名-2に対してREAD文が実行され、READ文によって読み込まれたレコードが、整列操作に引き渡される。この段階を始める前に、ファイル名-2のファイルは開いた状態であってはならない。この段階の中で、ファイル名-2のファイルは自動的にオープンされ、クローズされる。 - ファイル名-1のレコードが、KEY指定で指定した順に整列される。ここでの処理を、「整列操作」という。この段階の中で、ファイル名-2およびファイル名-3のファイルが処理されることはない。
- 以下の処理によって、整列されたレコードがファイル名-1のレコードとして使用可能になる。ここでの処理を、「整列操作の最後の段階」という。
OUTPUT PROCEDURE指定を書いた場合、出力手続きが実行される。「出力手続き」とは、手続き名-3に書いた手続き、または手続き名-3から手続き名-4までに書いた手続きのことである。出力手続きの中でファイル名-1のファイルに対するRETURN文を実行すると、ファイル名-1のレコードが使用可能になる。
GIVING指定を書いた場合、整列されたレコードがファイル名-1のレコードとて使用可能になり、ファイル名-3のファイルに書き出される。この段階を始める前に、ファイル名-3のファイルは、開いた状態であってはならない。この段階の中で、ファイル名-3のファイルは自動的にオープンされ、クローズされる。
- データ名-1のデータ項目を、「キー項目」という。キー項目を2つ以上指定する場合、キーの強さの順に左から右へ並べる。
- ASCENDING指定を書いた場合、整列操作に引き渡されたレコードのキー項目が比較の規則に従って比較され、キー項目の値が小さいレコードから大きいレコードの順に並べ替えられる。
- DESCENDING指定を書いた場合、整列操作に引き渡されたレコードのキー項目が比較の規則に従って比較され、キー項目の値が大きいレコードから小さいレコードの順に並べ替えられる。
- 2の比較の結果、すべてのキー項目の内容が同じであるレコードが2つ以上存在する場合には、整列されたレコードが以下の順に引き取られる。
- DUPLICATES指定を書いた場合:
USING指定を書いた場合、ファイル名-2の並びを書いた順に各ファイル中のレコードが引き取られる。1つのファイル名-2のファイル中にそのような複数のレコードが存在する場合、レコードが読み込まれた順に、レコードが引き取られる。INPUT PROCEDURE指定を書いた場合、入力手続きで引き渡された順にレコードが引き取られる。 - DUPLICATES指定を省略した場合:
レコードを引き取る順序は、規定されない。
- 文字比較の規則が適用される場合、キー項目の値の大小順序は、以下の規則に従って決定される。
- COLLATING SEQUENCE指定を書いた場合、符号系名-1に対応付けた文字の大小順序に従う。
- COLLATING SEQUENCE指定を省略した場合で、見出し部の翻訳用計算機段落にPROGRAM COLLATING SEQUENCE句を書いた場合は、その句で指定した文字の大小順序に従う。PROGRAM COLLATING SEQUENCE句を省略した場合は、計算機固有の文字の大小順序に従う。
INPUT PROCEDURE指定の規則
- INPUT PROCEDURE指定を書いた場合、整列操作が開始される前に、入力手続きに制御が移る。入力手続きの最後の文を実行した後、整列操作が開始される。
- 入力手続きの中には、ファイル名-1のレコードに対するRELEASE文を書きます。RELEASE文は、整列操作の最初の段階に、1つのレコードを引き渡す。
- 入力手続きの中で実行される文を、「入力手続きの範囲」という。入力手続きの範囲は、以下のとおりである。
- 入力手続きの中に書いた文。
- 入力手続きの中に書いた文(たとえばCALL文など)によって制御が移行した結果、実行されるすべての文。
- 入力手続きの中に書いた文によって実行される宣言手続きの中のすべての文。
- 入力手続きの範囲で、MERGE文、RETURN文またはSORT文を実行することはできない。
- 入力手続きの範囲で、SORT文と同じ手続き部内に書かれたEXIT PROGRAM文を実行することはできない。
USING指定の規則
- USING指定を書いた場合、ファイル名-2のファイル中のすべてのレコードが、ファイル名 -1のファイルに移される。
- ファイル名-2の各ファイルに対して、以下の処理が順に行われる。
- 初期処理が行われる。これは、ファイル名-2のファイルに対して、INPUT指定のOPEN文を実行したことと同じである。
- ファイル名-2のレコードが整列操作に引き渡される。これは、ファイル名-2のファイルに対して、NEXT指定およびAT END指定付きのREAD文を、レコードがなくなるまで実行したことと同じです。ファイル名-2に相対ファイルを指定した場合、SORT文を実行した後の相対キー項目の内容は規定されない。
- 終了処理が行われる。これは、ファイル名-2だけを指定したCLOSE文を実行したことと同じである。この処理は、整列操作が開始される前に行われる。
上記のa.~c.の処理の中で、ファイル名-2に関連するUSE AFTER STANDARD EXCEPTION手続きが実行されることがある。そのUSE手続きの中では、ファイル名-2のファイルを操作する文またはファイル名-2のレコードを参照する文を実行することはできない。(*1)
- ファイル名-1のレコード形式が固定長で、ファイル名-2のレコードの長さがファイル名-1のレコード長より短い場合、そのレコードがファイル名-1のファイルに引き渡されるとき、レコードの右側の余りの部分には空白が詰められる。
OUTPUT PROCEDURE指定の規則
- OUTPUT PROCEDURE指定を書いた場合、整列操作が終了した後、出力手続きに制御が移る。出力手続きの最後の文を実行した後、SORT文の次の実行文に制御が移る。
- 出力手続きに制御が移ったとき、ファイル名-1のレコードは完全に整列されていて、RETURN文によって順番に引き取れるような状態になっている。出力手続きの中には、ファイル名-1のファイルに対するRETURN文を書く。RETURN文は、整列操作の最後の段階から、1つのレコードを引き取る。
- 出力手続きの中で実行される文を、「出力手続きの範囲」という。出力手続きの範囲は、以下のとおりである。
- 出力手続きの中に書いた文。
- 出力手続きの中に書いた文(たとえばCALL文など)によって制御が移行した結果、実行されるすべての文。
- 出力手続きの中に書いた文によって実行される宣言手続きの中のすべての文。
- 出力手続きの範囲で、MERGE文、RELEASE文またはSORT文を実行することはできない。
- 出力手続きの範囲で、SORT文と同じ手続き部内に書かれたEXIT PROGRAM文を実行することはできない。
GIVING指定の規則
- GIVING指定を書いた場合、整列操作が終了した後、ファイル名-1のファイル中のすべてのレコードが、ファイル名-3のファイルに移される。
- ファイル名-3の各ファイルに対して、以下の処理が順に行われる。
- 初期処理が行われる。これは、ファイル名-3のファイルに対して、OUTPUT指定のOPEN文を実行したことと同じである。
- ファイル-1のレコードを整列操作から引き取る。これは、ファイル名-1のファイルに対して、レコード名だけを指定したWRITE文を、ファイル名-1のレコードがなくなるまで実行したことと同じである。
ファイル名-3に相対ファイルを指定した場合、引き取られる相対レコード番号は、最初のレコードから順に、1、2、3、…というように設定される。ファイル名-3のファイルに相対キー項目を指定した場合、レコードが引き取られるごとに、相対レコード番号が相対キー項目に設定される。SORT文の実行後の相対キー項目の内容は、ファイル名-3のファイルに引き取られた最後のレコードを表す。 - 終了処理が行われる。これは、ファイル名-3だけを指定したCLOSE文を実行したことと同じである。
上記のa.~c.の処理の中で、ファイル名-3に関連するUSE AFTER STANDARD EXCEPTION手続きが実行されることがある。そのUSE手続きの中では、ファイル名-3のファイルを操作する文またはファイル名-3のレコードを参照する文を実行することはできない。(*1)
- ファイル名-3のファイルの外部で定義された区域を超えて、最初にレコードを書き出そうとすると、以下の処理が行われる。(*1)
- ファイル名-3に関連するUSE AFTER STANDARD EXCEPTION手続きを書いた場合、そのUSE手続きが実行される。そして、USE手続きから制御が戻った後、ファイル名-3だけを指定したCLOSE文を実行したかのように、終了処理が行われる。
- ファイル名-3に関連するUSE AFTER STANDARD EXCEPTION手続きを書かなかった場合、ファイル名-3だけを指定したCLOSE文を実行したかのように、終了処理が行われる。
- ファイル名-3のレコード形式が固定長で、ファイル名-1のレコードの長さがファイル名-3のレコード長より短い場合、そのレコードがファイル名-3のファイルに引き取られるとき、レコードの右側の余りの部分には空白が詰められる。
(*1) SIT COBOLでは、USE AFTER STANDARD EXCEPTIONが書かれていても実行されない。(制限事項)
ソート例
USING/GIVINGを利用した例と、INPUT PROCEDURE/OUTPUT PROCEDUREを使用した例を示す。
(サンプル: SORT文.cob)
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. SORT_01.
000020 ENVIRONMENT DIVISION.
000030 INPUT-OUTPUT SECTION.
000040 FILE-CONTROL.
000050 SELECT F1 ASSIGN TO "F1.txt". *> SORTの入力と出力に使用
000060 SELECT SORT-F ASSIGN TO "SD1". *> "SD1"はメモのみである
000070 DATA DIVISION.
000080 FILE SECTION.
000090 FD F1.
000100 01 F1-REC.
000110 02 F1-DATA1 PIC X(5).
000120 02 F1-DATA2 PIC S9(3)V9(2).
000130 02 F1-DMY PIC X(10).
000140*
000150 SD SORT-F.
000160 01 SORT-R.
000170 02 DATA1 PIC X(5). *> ソートキー1: 英数字項目
000180 02 DATA2 PIC S9(3)V9(2). *> ソートキー2: 数字項目
000190 02 PIC X(10).
000200 WORKING-STORAGE SECTION.
000210 01 WK1. *> ソート用データ
000220 02 PIC X(20) VALUE "ddddd, 333, ".
000230 02 PIC X(20) VALUE "ccccc,-123, ".
000240 02 PIC X(20) VALUE "aaaaa, 22.12, ".
000250 02 PIC X(20) VALUE "ggggg, 001, ".
000260 02 PIC X(20) VALUE "bbbbb,-100.00,".
000270 02 PIC X(20) VALUE "ddddd,-444.4, ".
000280 02 PIC X(20) VALUE "ccccc, 123, ".
000290 02 PIC X(20) VALUE "aaaaa,+33, ".
000300 02 PIC X(20) VALUE "ggggg, 0, ".
000310 02 PIC X(20) VALUE "bbbbb,+100, ".
000320 01 WK2 REDEFINES WK1.
000330 02 W-DATA PIC X(20) OCCURS 10.
000340 01 I PIC 9(2).
000350 PROCEDURE DIVISION.
000360 MAIN00.
000370* USING句およびGIVING句を使用する例
000380 DISPLAY "*** SORT USING/GIVING".
000390 PERFORM データの準備.
000400 DISPLAY "整列前のデータ".
000410 PERFORM データの表示.
000420* ソートの実行
000430 SORT SORT-F
000440 ASCENDING DATA1 *> DATA1は昇順にソートする
000450 DESCENDING DATA2 *> DATA2は降順にソートする
000460 USING F1
000470 GIVING F1.
000480 DISPLAY "整列後のデータ".
000490 PERFORM データの表示.
000500 DISPLAY "".
000510
000520* INPUT PROCEDURE/OUTPUT PROCEDUREを使用する例
000530 DISPLAY "*** SORT INPUT PROCEDURE / OUTPUT PROCEDURE".
000540 PERFORM データの準備.
000550 DISPLAY "整列前のデータ".
000560 PERFORM データの表示.
000570 SORT SORT-F
000580 DESCENDING DATA1 *> DATA1は降順にソートする
000590 ASCENDING DATA2 *> DATA2は昇順にソートする
000600 INPUT PROCEDURE データの入力
000610 OUTPUT PROCEDURE ソート済データの受け取り.
000620 DISPLAY "整列後のデータ".
000630 PERFORM データの表示.
000640 STOP RUN.
000650*============================================================
000660 データの準備.
000670 OPEN OUTPUT F1.
000680 PERFORM VARYING I FROM 1 UNTIL I > 10
000690 UNSTRING W-DATA(I) *> W-DATA(I)を','で分離しF1-DATA1、F1-DATA2に設定
000700 DELIMITED BY ","
000710 INTO F1-DATA1, F1-DATA2
000720 MOVE ALL "+" TO F1-DMY
000730 WRITE F1-REC
000740 END-PERFORM.
000750 CLOSE F1.
000760*-----------------------------------------------------------
000770 データの表示.
000780 OPEN INPUT F1.
000790 PERFORM FOREVER
000800 READ F1 *> F1よりデータの読込み
000810 AT END
000820 EXIT PERFORM
000830 END-READ
000840 DISPLAY F1-REC *> READしたデータの表示
000850 END-PERFORM
000860 CLOSE F1.
000870*-----------------------------------------------------------
000880 データの入力.
000890* F1のデータをSORTワークに引き渡す
000900 OPEN INPUT F1.
000910 PERFORM FOREVER
000920 READ F1
000930 AT END
000940 EXIT PERFORM
000950 END-READ
000960 RELEASE SORT-R FROM F1-REC *> RELEASE文によるデータの引き渡し
000970 END-PERFORM
000980 CLOSE F1.
000990*-----------------------------------------------------------
001000 ソート済データの受け取り
001010* ソート済のデータを受け取り、F1に書き出す
001020 OPEN OUTPUT F1.
001030 PERFORM FOREVER
001040 RETURN SORT-F *> RETURN文によるデータの受け取り
001050 AT END
001060 EXIT PERFORM
001070 END-RETURN
001080 WRITE F1-REC FROM SORT-R *> 受け取ったデータの書き出し
001090 END-PERFORM.
001100 CLOSE F1.SORT文の実行は、大きく3つのフェーズに分かれる。
1つ目のフェーズは、ソートワーク(ソート対象のデータを溜め込む領域)へのデータの引き渡しである。このフェーズを「整列操作の最初の段階」という。
2つ目のフェーズは、そのソートワーク上のデータのソートである。このフェーズを「整列操作」という。
そして、3つ目のフェーズは、ソートされたソートワーク上のデータの受け取りである。このフェーズを「整列操作の最後の段階」という。
以下、簡単に上記のプログラムの説明をする。
ソートするデータは、W-DATAとして用意されており、この例ではCSV形式(カンマ区切り)のデータとなっている。(000210-000310行)
「データの準備」段落(000660-000750行)では、これらのW-DATAをファイルF1に書き込むため、UNSTRING文を使ってW-DATAの各要素を、カンマ(,)で区切り、それをF1のレコード領域のF1-DATA1、F1-DATA2に設定し、さらにF1-DMYにALL
“+”を設定し、それからWRITE文で出力している。
最初のSORT文(000430-000470行)では、USING句にF1が指定されているので、1フェーズ目で、そのF1のデータをソートワークに引き渡す。
次に2フェーズ目でソートワーク上のデータをソートする。これはSIT
COBOLの中で行われるので、特に何もしなくてよい。最後に3フェーズ目で、GIVING句に指定されたファイルF1にデータを受け渡す。
ソートキーは、1-5桁目のデータDATA-1がASCENDING指定なので昇順、6-10桁目のデータDATA-2がDESCENDINGなので降順で指定されている。指定されたキー順にソートされるので、まずは、DATA-1の昇順にレコードを並べ、DATA-1の値が同じレコードでは、DATA-2の値が降順となるように並ぶ。
もし、キーの順序を、DESCENDING
DATA-2 ASCENDING
DATA-1としたら、まずはDATA-2の降順にレコードを並べ、さらにDATA-1の昇順にレコードを並べることになるので、全く異なるソート結果となる。
2つ目のSORT文(000570-610行)では、1フェーズ目で、INPUT
PROCEDUREに指定された「データの入力」段落(000880-000980行)が実行され、その中のRELEASE文によりデータをソートワークに引き渡す。
そして2フェーズ目で、ソートワーク上のデータがソートされ、3フェーズ目で、今度は、OUTPUT
PROCEDUREに指定された「ソート済データの受け取り」段落(001000-001100行)が実行され、その中のRETURN文で、ソートワークの中のデータを1つ1つ受け取る。受け取ったレコードは、F1に書き出している。
ソートキーは、DATA-1がDESCENDING指定、DATA-2がASCENDINGなので、最初のSORT文とはソート結果が異なる。
実行したときの出力結果は次のとおりである。
*** SORT USING/GIVING
整列前のデータ
ddddd33300++++++++++
ccccc1230p++++++++++
aaaaa02212++++++++++
ggggg00100++++++++++
bbbbb1000p++++++++++
ddddd4444p++++++++++
ccccc12300++++++++++
aaaaa03300++++++++++
ggggg00000++++++++++
bbbbb10000++++++++++
整列後のデータ
aaaaa03300++++++++++
aaaaa02212++++++++++
bbbbb10000++++++++++
bbbbb1000p++++++++++
ccccc12300++++++++++
ccccc1230p++++++++++
ddddd33300++++++++++
ddddd4444p++++++++++
ggggg00100++++++++++
ggggg00000++++++++++
*** SORT INPUT PROCEDURE / OUTPUT PROCEDURE
整列前のデータ
ddddd33300++++++++++
ccccc1230p++++++++++
aaaaa02212++++++++++
ggggg00100++++++++++
bbbbb1000p++++++++++
ddddd4444p++++++++++
ccccc12300++++++++++
aaaaa03300++++++++++
ggggg00000++++++++++
bbbbb10000++++++++++
整列後のデータ
ggggg00000++++++++++
ggggg00100++++++++++
ddddd4444p++++++++++
ddddd33300++++++++++
ccccc1230p++++++++++
ccccc12300++++++++++
bbbbb1000p++++++++++
bbbbb10000++++++++++
aaaaa02212++++++++++
aaaaa03300++++++++++ここで、6-10カラム目(F1-DATA2)は、S9(3)V9(2)
という数字データ項目(外部10進数)なので、5桁の最初の3桁が整数部で、後の2桁が小数部である。また、正負については最後の5桁目(全体の10カラム目)で表現(重ね符号)されている。
上記のデータの中には、5桁目(全体の10カラム目)が’p’となっているものがあるが、これはASCIIコードでは、0x70
であり’7’は負、’0’は下1桁の数字を表している。例えば、’1230p’は、-123.00
を示している。
重ね符号を含むデータの表現方法については、USAGE句で決められている。詳しくは、「データ部のUSAGE句」を参照されたい。
6.7.5 SORT文(テーブルのソート)
キー項目の値の順にテーブル(OCCURS句を持つ項目)を整列する。
一般形式
SORT テーブル名-1
{ ON { ASCENDING | DESCENDING } KEY { データ名-1 }… }…
[ WITH DUPLICATES IN ORDER ]
[ COLLATING SEQUENCE IS 符号系名-1 ]
(※) SIT COBOLは、符号系名-1には対応していない。(制限事項)
(※) SIT
COBOLは、DUPLICATS句には対応していない。(制限事項)
構文規則
- SORT文は、宣言部分を除く手続き部のどこにでも書くことができる。
- テーブル名-1は、OCCURS句を直接または間接的に持つ項目でなければならない。また1次元のデータ項目でなければならない。
- データ名-1は、テーブル名-1に従属するデータ項目として定義されていなければならない。
一般規則
- SORT文を実行すると、以下の処理が順に行われる。
- 以下の処理によって、テーブル名-1に指定されたデータ項目のすべての要素が整列操作に引き渡される。ここでの処理を、「整列操作の最初の段階」という。
- テーブル名-1に指定されたデータ項目のすべての要素が、KEY指定で指定した順に整列される。ここでの処理を、「整列操作」という。
- 整列されたデータが、テーブル名-1の各要素に設定される。ここでの処理を、「整列操作の最後の段階」という。
- データ名-1のデータ項目を、「キー項目」という。キー項目を2つ以上指定する場合、キーの強さの順に左から右へ並べる。
- ASCENDING指定を書いた場合、整列操作に引き渡されたレコードのキー項目が比較の規則に従って比較され、キー項目の値が小さいレコードから大きいレコードの順に並べ替えられる。
- DESCENDING指定を書いた場合、整列操作に引き渡されたレコードのキー項目が比較の規則に従って比較され、キー項目の値が大きいレコードから小さいレコードの順に並べ替えられる。
- の比較の結果、すべてのキー項目の内容が同じであるレコードが2つ以上存在する場合には、整列されたレコードが以下の順に引き取られる。
- DUPLICATES指定を書いた場合:
データが読み込まれた順に、データが引き取られる。 - DUPLICATES指定を省略した場合:
データを引き取る順序は、規定されない。
- 文字比較の規則が適用される場合、キー項目の値の大小順序は、以下の規則に従って決定される。
- COLLATING SEQUENCE指定を書いた場合、符号系名-1に対応付けた文字の大小順序に従う。
- COLLATING SEQUENCE指定を省略した場合で、見出し部の翻訳用計算機段落にPROGRAM COLLATING SEQUENCE句を書いた場合は、その句で指定した文字の大小順序に従う。PROGRAM COLLATING SEQUENCE句を省略した場合は、計算機固有の文字の大小順序に従う。
テーブルソート例
(サンプル: テーブルソート.cob)
000000 IDENTIFICATION DIVISION.
000010 PROGRAM-ID. TABLE_SORT001.
000020 DATA DIVISION.
000030 WORKING-STORAGE SECTION.
000040 01 A.
000050 02 AA.
000060 03 PIC x(30) VALUE "55555aaaaa".
000070 03 PIC x(30) VALUE "44444bbbbb".
000080 03 PIC x(30) VALUE "11111bbbbb".
000090 03 PIC x(30) VALUE "33333ccccc".
000100 03 PIC x(30) VALUE "44444ccccc".
000110 03 PIC x(30) VALUE "22222bbbbb".
000120 03 PIC x(30) VALUE "44444aaaaa".
000130 02 AA-RE REDEFINES AA OCCURS 7.
000140 03 A-TABLE.
000150 04 DATA1 PIC 9(5).
000160 04 DATA2 PIC X(5).
000170 04 PIC X(20).
000180 01 I PIC 9.
000190 PROCEDURE DIVISION.
000200 MAIN00.
000210 SORT A-TABLE
000220 ASCENDING DATA1
000230 DESCENDING DATA2.
000240 PERFORM VARYING I FROM 1 UNTIL I > 7
000250 DISPLAY A-TABLE(I)
000260 END-PERFORM.
000270 STOP RUN.テーブルソートの実行は、大きく3つのフェーズに分かれる。
1つ目のフェーズは、テーブルの各要素(レコード)のソートワーク(ソート対象のデータを溜め込む領域)へのデータの引き渡しである。このフェーズを「整列操作の最初の段階」という。
2つ目のフェーズは、そのソートワーク上のデータのソートである。このフェーズを「整列操作」という。
そして、3つ目のフェーズは、ソートされたソートワーク上のデータの受け取りである。このフェーズを「整列操作の最後の段階」という。
以下、簡単に上記のプログラムの説明をする。
ソートするデータは、AAとして用意されており、これを、AA-REで再定義している。(00050-000170行)
SORT文(000210-000230行)では、SORT文にA-TABLEが指定されている。A-TABLEは、A-REに含まれる項目であり、7つの要素を持つ1次元のテーブル(表)である。
1フェーズ目で、そのA-TABLEの各要素である、A-TABLE(1),
A-TABLE(2),…A-TABLE(7)のデータをソートワークに引き渡す。
次に2フェーズ目でソートワーク上のデータをソートする。これはSIT
COBOLの中で行われるので、特に何もしなくてよい。
最後に3フェーズ目で、A-TABLEの各要素に整列された順にデータを受け渡す。
ソートキーは、1-5桁目のデータDATA-1がASCENDING指定なので昇順、6-10桁目のデータDATA-2がDESCENDINGなので降順で指定されている。指定されたキー順にソートされるので、まずは、DATA-1の昇順にレコードを並べ、DATA-1の値が同じレコードでは、DATA-2の値が降順となるように並ぶ。
もし、キーの順序を、DESCENDING
DATA-2 ASCENDING
DATA-1としたら、まずはDATA-2の降順にレコードを並べ、さらにDATA-1の昇順にレコードを並べることになるので、全く異なるソート結果となる。
実行したときの出力結果は次のとおりである。
11111bbbbb
22222bbbbb
33333ccccc
44444ccccc
44444bbbbb
44444aaaaa
55555aaaaa